Populse_MIA’s Pipeline Manager¶
This page is a user guide for Populse_mia’s Pipeline Manager, a tool to build and run processing pipelines in a graphical way.
Tab presentation¶
- The Pipeline Manager tab is composed of four main elements:
Here is an overview of the Pipeline Manager tab:
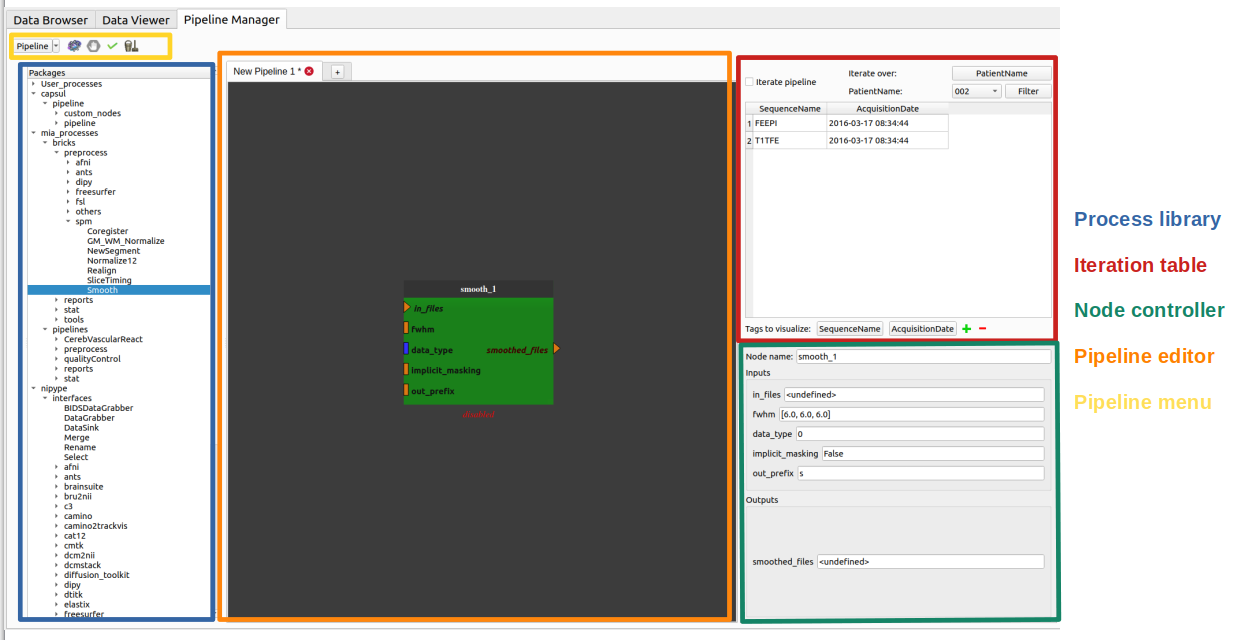
The process library¶
The process library contains all the available pipeline processes.
When Populse_MIA is launched for the first time, Nipype’s interfaces are stored in the process library.
If Capsul and mia_processes are used, they are also stored in the process library.
To use any of the available processes, drag it from the process library and drop it to the pipeline editor.
When a pipeline is saved, it is stored in the process library under “User_processes” and can be used as a process.
The pipeline editor¶
The pipeline editor is a graphical tool to create pipelines. It is composed of several tabs to work on several pipelines at the same time. In the following, the current tab will be called “current editor”.
The menu on the top left of the Pipeline Manager tab contains several actions impacting the current editor:
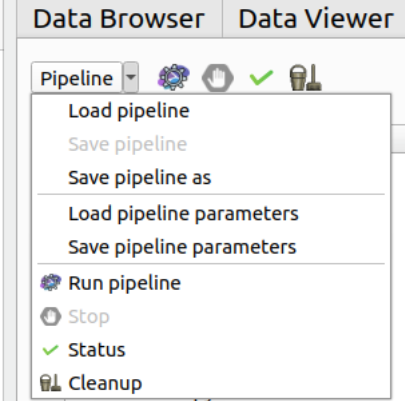
- Load pipeline
Loads a saved pipeline in a new editor (or in the current editor if there is only one editor and it is empty)
- Save pipeline
Saves the pipeline of the current editor (shortcut: Ctrl+S)
- Save pipeline as
Saves the pipeline of the current editor under another name (shortcut: Ctrl+Shift+S)
- Load pipeline parameters
Loads a parameters set and apply them to the pipeline global inputs/outputs
- Save pipeline parameters
Saves the pipeline global inputs/outputs to a json file
- Run pipeline
Creates the output file names for each process in the current pipeline and stores them to the database
For the processes that interact with the database, verifies that the fields are filled
Executes the current pipeline
- Stop pipeline
Stop the pipeline that is currently running
- Status
Open the Execution status windows to check the status of the workflows run
- Cleanup
If there is an issue during the run of the pipeline, this button can be used to cleanup the database (ie. remove of the database all non-existing files)
Buttons for “Run pipeline”, “Stop”, “Status” and “Cleanup” are also displayed to the right of the menu.
Shortcuts¶
Hold Ctrl while using the mouse trackwheel to zoom/zoom out.
Click on a node to display its parameters in the node controller.
Hold Ctrl while clicking on a node to display it and its link in the foreground.
To add a link between two nodes, drag from an output plug to an input plug.
How to use the pipeline editor¶
The pipeline edtior uses the PipelineDevelopperView tool from Capsul to create pipelines in a graphical way. Here is a tutorial to help to create and save a simple pipeline (no run):
Add a SPM smooth process (from Nipype library) by dragging it from the process library and dropping it into the pipeline editor
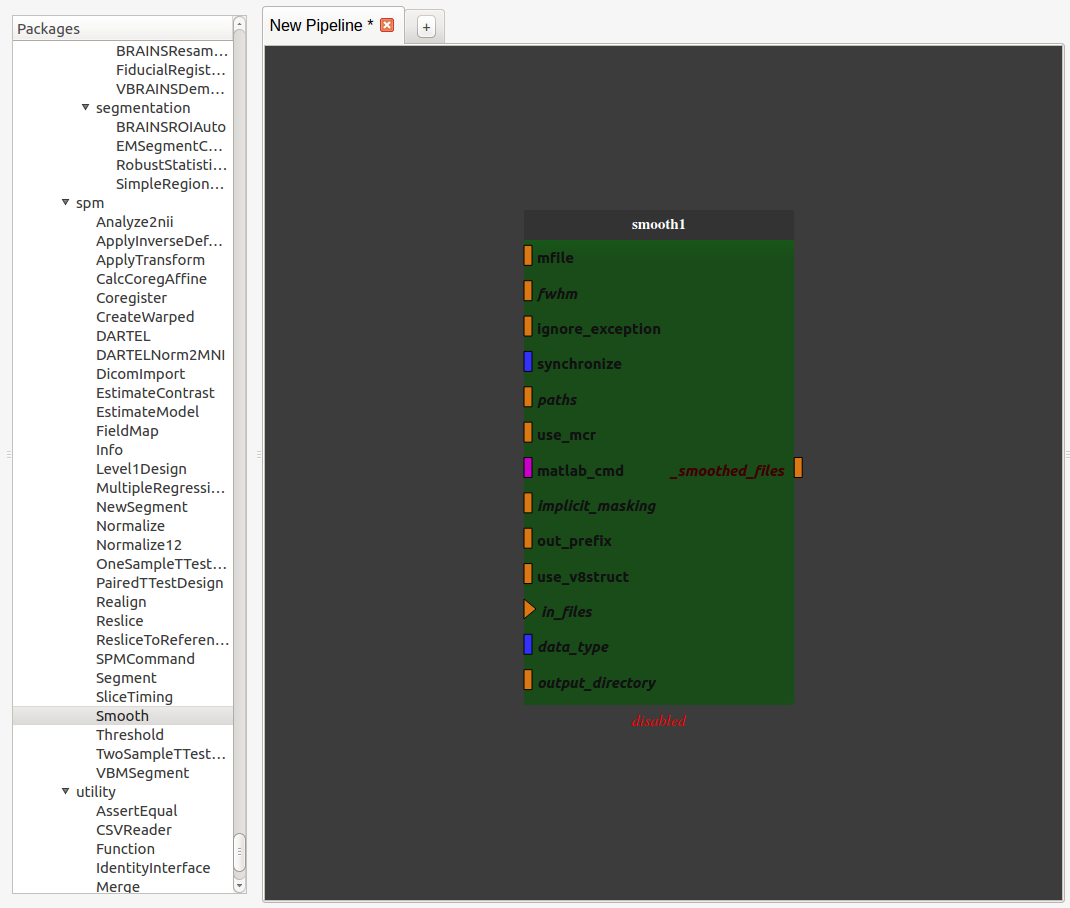
Export the input and output plug(s) we want to be able to modify by right-clicking on them and click on “export plug”, rename it if we want and click on “OK”.
Note 1: a plug is either mandatory or optional. When it is mandatory, it is represented as a triangle and has to be exported or connected to another plug to run the pipeline. When it is optional, it is represented as a rectangle and can be exported or connected or not. Usually optional plugs have default values, e.g. “fwhm” plug from SPM’s smooth is [6, 6, 6], so do not need to be exported and/or modified. It all depends if we want to have access to this plug when the pipeline will be used as a process.
Note 2: to make a pipeline valid, we have to export plugs that are the pipeline global input/outputs. In this example, the “in_files” plug needs to be exported because it is mandatory. The only output plug has to be also exported. The node will then be activated and its color become lighter. It is also possible to export optional plug such as “fwhm” and “output_directory” even if they already have default value.
Note 3: Nipype’s processes needs values for “output_directory”, “use_mcr”, “paths”, “matlab_cmd” and “mfile” plugs. These are updated from Populse_MIA’s during pipeline initialization.
Note 4: if we right-click on a node or on the pipeline editor background, we can also export plugs (mandatory or not, input, output or both). This method is usually faster to export plugs.
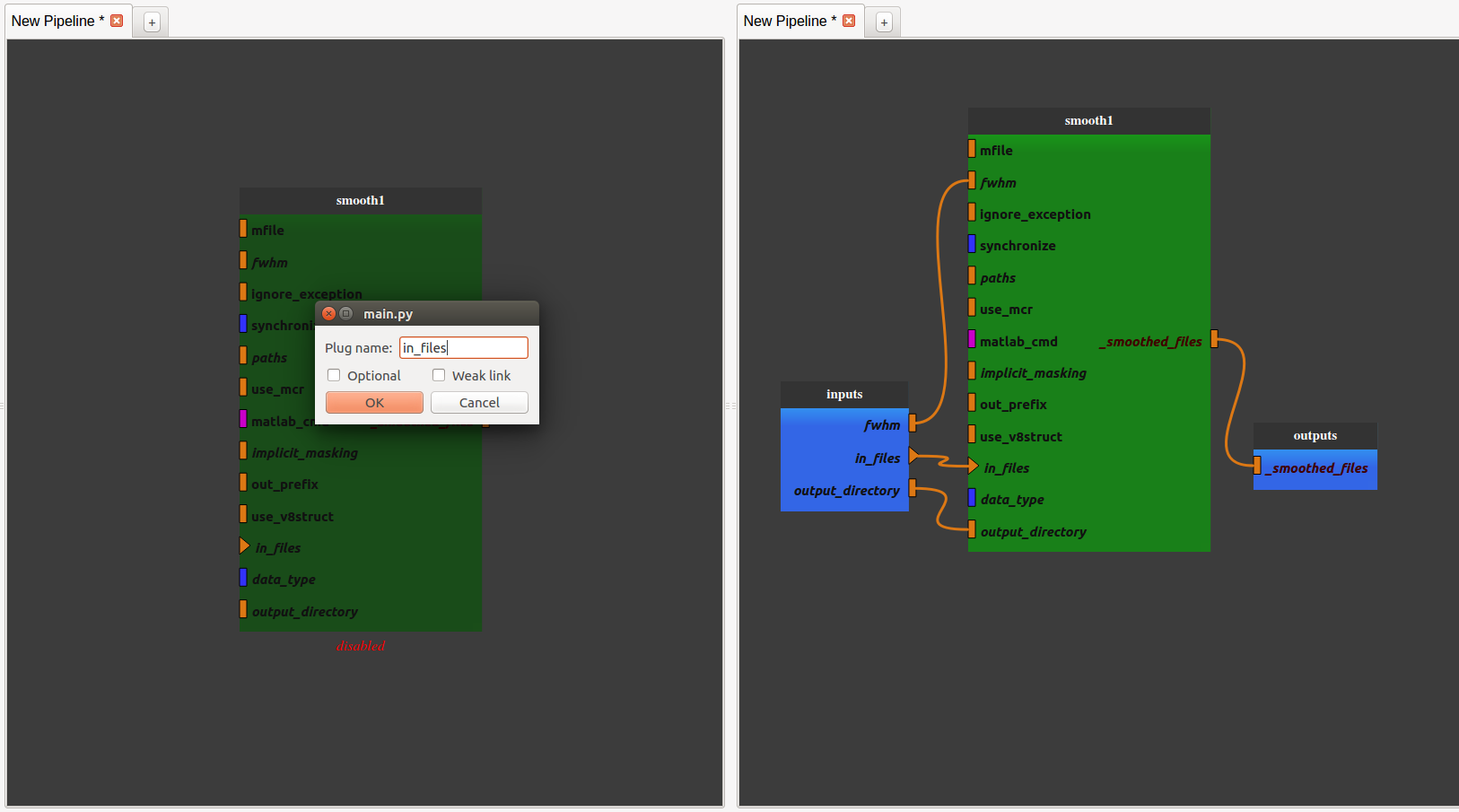
Now the pipeline is only composed of one process with exported inputs/output. It is still possible to add another process to modify it.
- Add another SPM smooth process and make it follow the first one.
Right-click on the link between the output of the “smooth1” node and the pipeline output and select “remove link”. The pipeline is disabled.
Connect the “_smoothed_files” plug of the “smooth1” node to the “in_files” plug of the “smooth2” node by dragging from “_smoothed_files” and dropping to “in_files”.
Connect the “_smoothed_files” plug of the “smooth2” node to the “_smoothed_files” global output by dragging from “_smoothed_files” and dropping to “in_files”. The pipeline in enabled.
Connect the “output_directory” global input to the “output_directory” plug of the “smooth2” node by dragging from “output_directory” and dropping to “output_directory”.
Connect the “fwhm” global input to the “fwhm” plug of the “smooth2” node by dragging from “fwhm” and dropping to “fwhm”.
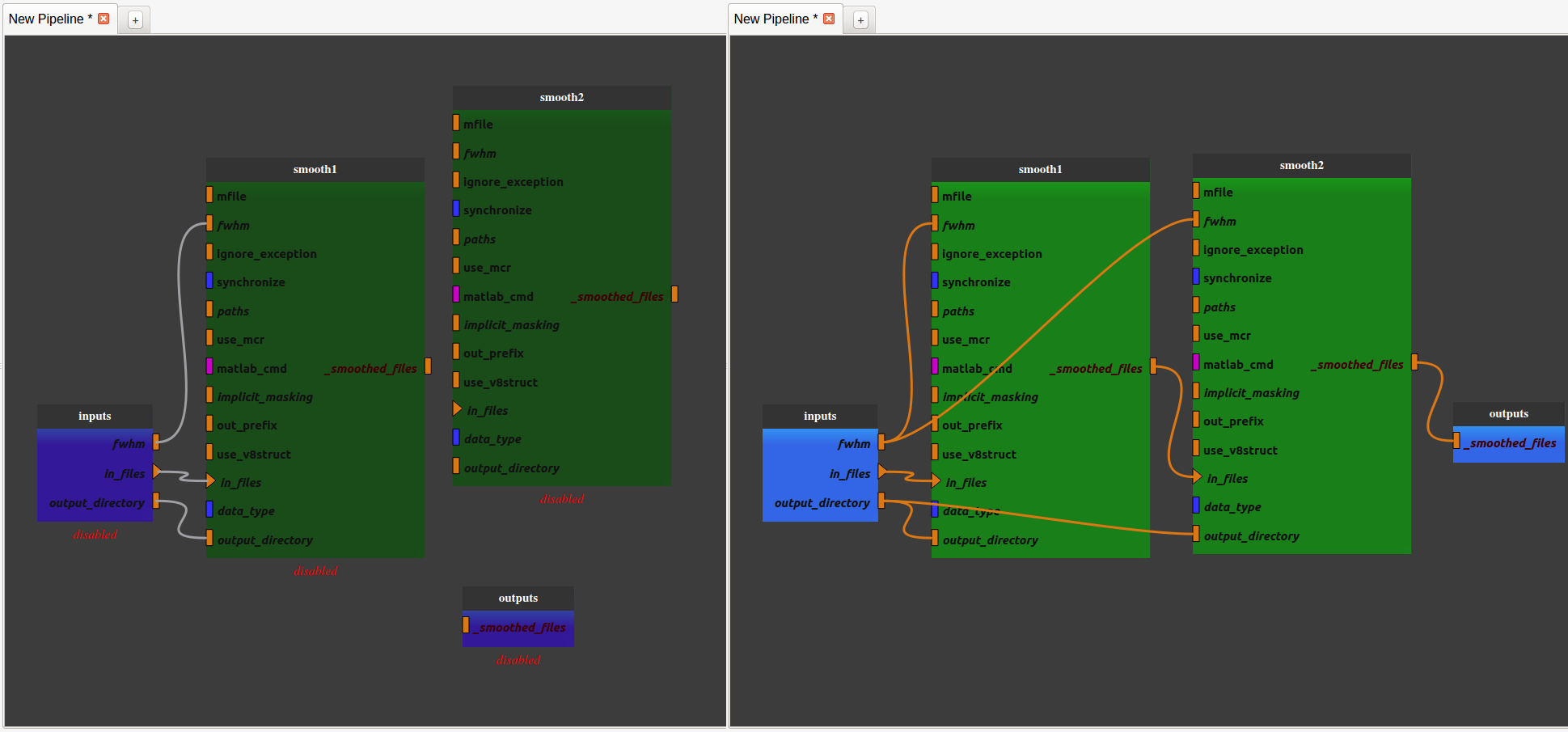
We now have a pipeline that can smooth an image twice with the same fwhm parameter.
Save the pipeline in the proposed folder by clicking on the bottom left “Pipeline” menu
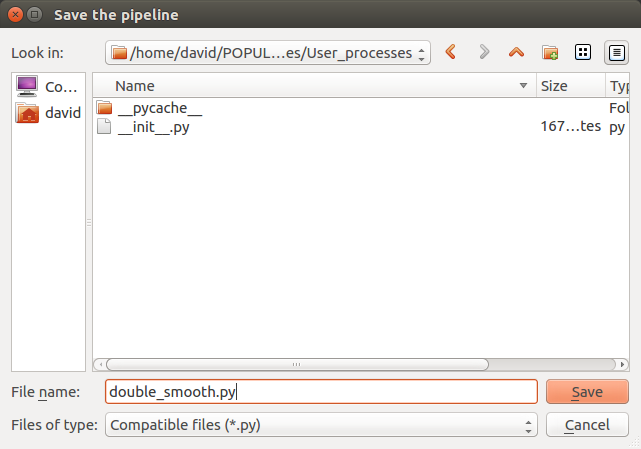
- The pipeline is now stored in the process library under “User_processes”. We can use it as a process and add it to a new pipeline editor.
We can visualize the pipeline by double-clicking on the nodee
We can edit the pipeline by right-clicking on the node and selecting “Open sub-pipeline”. It will open “double_smooth.py” in a new editor tab.
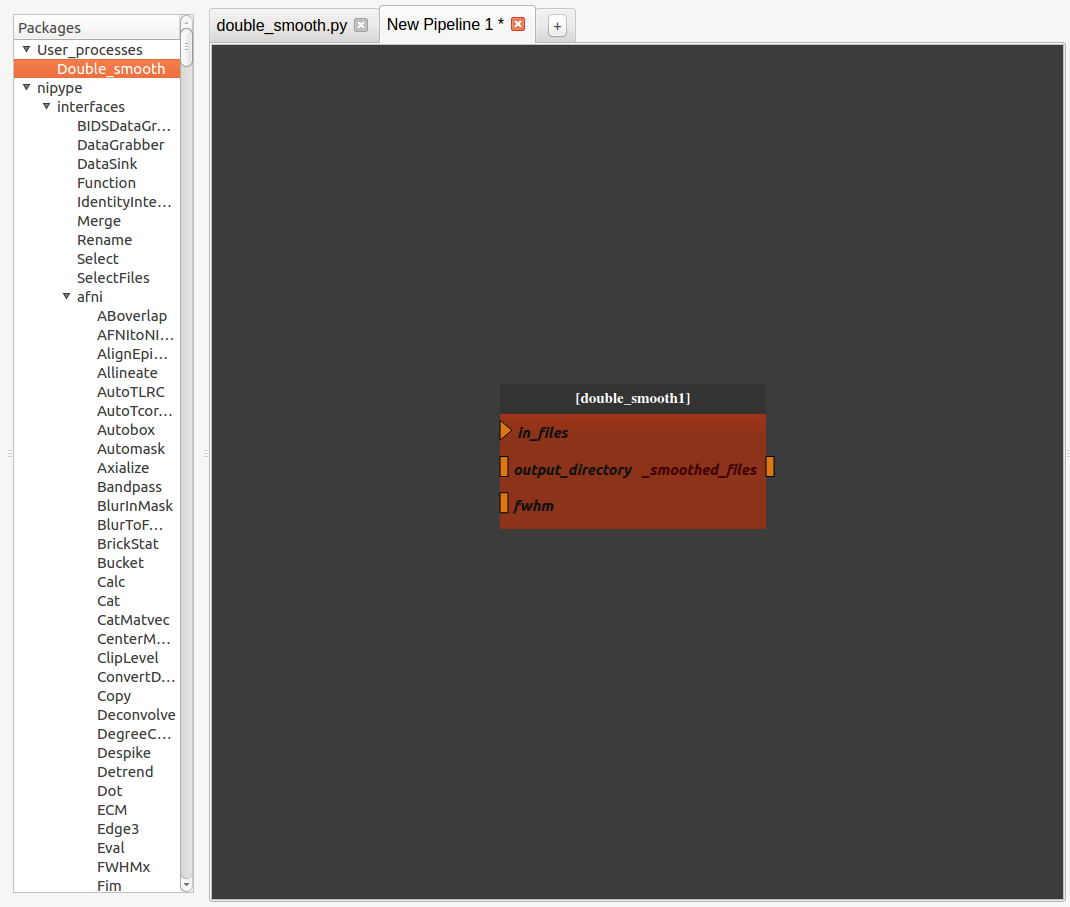
If we want to change one parameter of the pipeline, it is still possible to make a change following these steps:
For instance, if we want to change the prefix of the file name generated in the second process, go back to the “double_smooth.py” pipeline, export the “out_prefix” plug and save the pipeline.
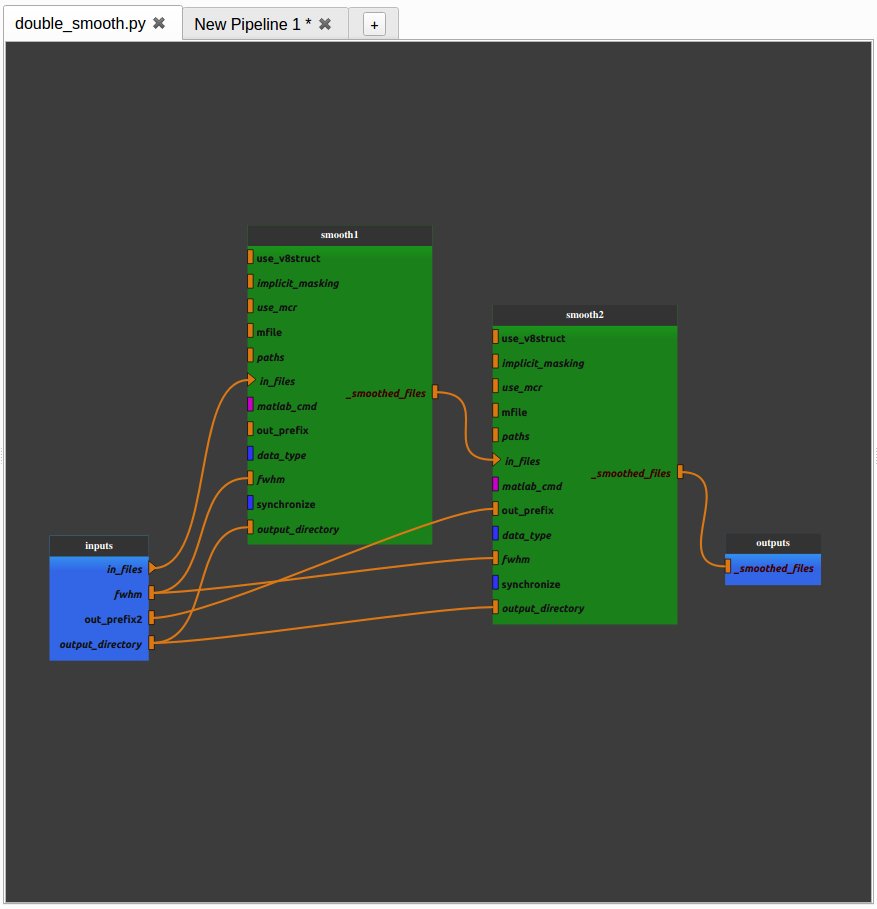
When we go back to the “New pipeline 1” pipeline, we can see that the “out_prefix” plug has been automatically added and we can now control its value.
To set input values and to run the pipeline, follow the steps of The node controller.
The node controller¶
The node controller is a controller that updates pipeline nodes and is located on the bottom right of the Pipeline Manager tab. It can change their inputs/outputs values and their name.
Note: to enable the node controller, click on a node. It will display its parameters.
Note: when changing a value in the node controller, be sure to press Enter to validate the change.
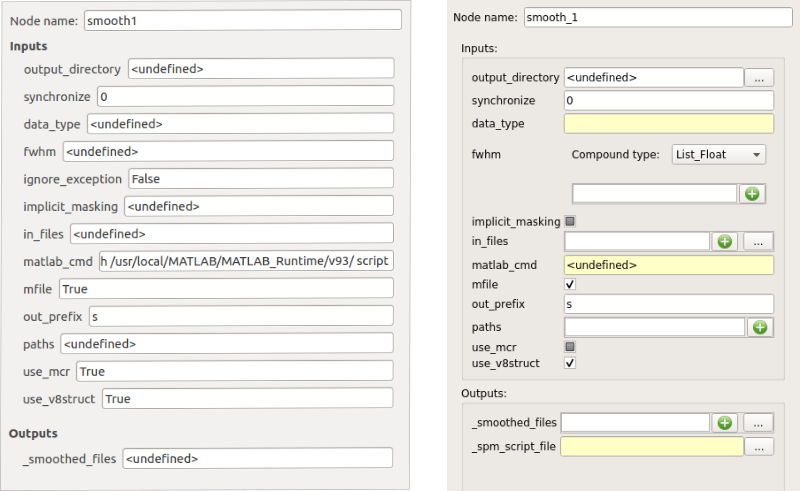
The controller in V1 (left) and V2 (right) mode¶
How to use the node controller¶
This part is based on the Double_smooth.py file created in The pipeline editor.
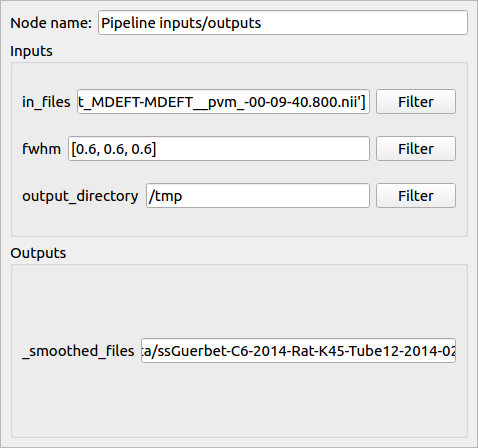
When we have clicked on a pipeline global inputs/outputs node (blue node) it is possible to filter each input plug to set documents directly from the database. For that, click on the “Filter” push button.
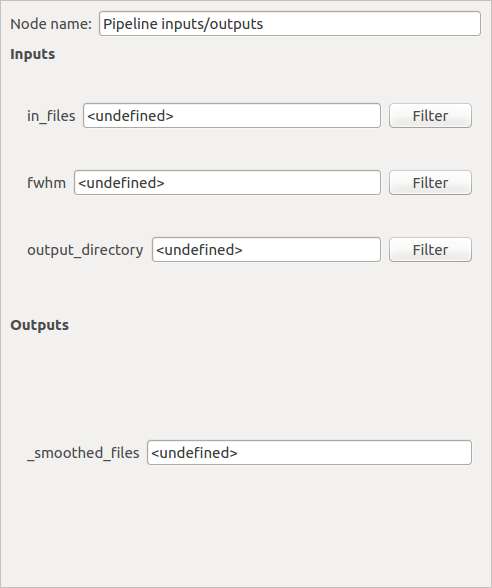
A pop-up similar to the Data Browser will be displayed and we will be able to choose which documents of the database to set on the plug by using Rapid or Advanced Search.
We can either filter the database (by setting the filter parameters and clicking on “Search”) or click on the selected documents.
The second push button at the bottom left of the window specifies which tag values to set on the selected plug.
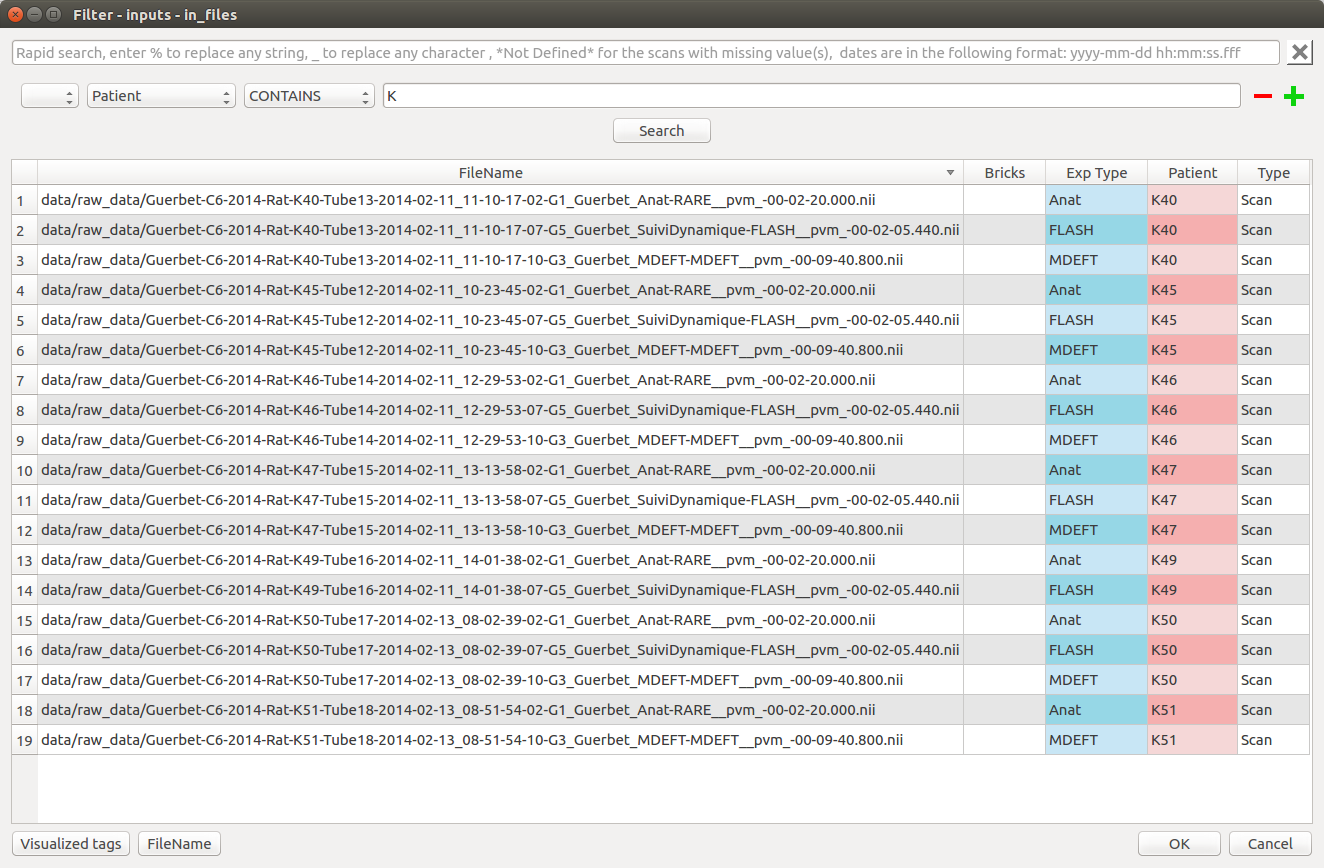
Press “OK” to set the selected documents to the plug value. The plug value has been updated in the node controller
- We can also modify the plug values by hand
Note: the “output_directory” of a Nipype process corresponds to the folder where Nipype writes the Matlab scripts during execution and has to be set.
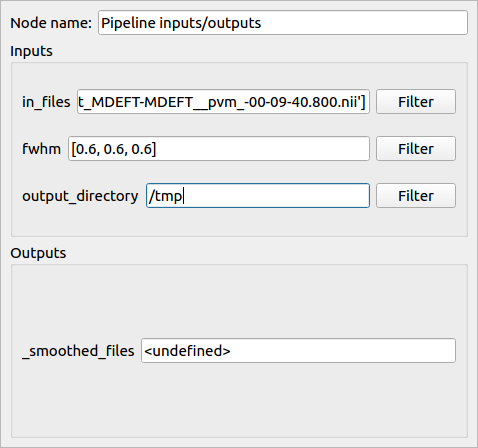
The pipeline inputs are now correctly set and it can be run. Select “Run pipeline” in the Pipeline menu (or click directly on the “Run pipeline” button of the Pipeline menu).
A connection dialog is displayed. Select the resource you want to run the pipeline on and click “Ok”.
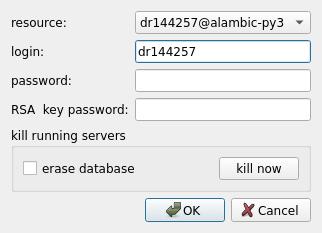
- During this step:
The output files are created (but still empty) and stored in the database with information about their ancestors (their input files and parameters)
The output file names are generated and updated in the node controller (in this example the file names begin with “ss” which means that they have been smoothed twice).
The pipeline is run.
During the run, the “Status” button near the Pipeline menu changes and a waiting bar appears at the top right corner. You can also used the “stop pipeline” button.

At the end of the run, a windows with “Pipeline execution was ok’ appears during 10 seconds and the waiting bar at the top right corner disappears.
Pipeline iteration¶
A pipeline is generally designed to perform a series of tasks on a single data, or on a set of data going together (an anatomical MRI image and a series of fMRI data for instance). To process databases we need to iterate pipelines on many input data. For this we use iterations which virtually duplicate the given pipeline as many times as there are data to process. Populse is able to process such iterations in parallel as long as they are independent. This is done by transforming a pipeline (or a process) into an iterative pipeline, using an iteration node.
The Pipeline Manager simplifies this operation using the Iterate pipeline button and The iteration table.
There are two ways to iterate a pipeline (or a brick/process): one is by creating a regular iterative pipeline (with “direct” inputs and without use of the iteration table), the other is using Input_Filter linked to the database.
Via a regular iterative pipeline (without use of the iteration table)¶
Starting with a new, empty pipeline tab in the Pipeline Manager:
Add the pipeline mia_processes > pipelines > preprocess > Bold_spatial_preprocessing1 to the pipeline editor
The
func_filesparameter is a list. We will use only one item per iteration. In order to disambiguate the “list of list” situation in the iteration, we will use here a node which transforms a single file (input for this iteration) into a list of just one element.Use the “capsul > pipeline > custom_nodes > reduce_node > ReduceNode” or the “mia_processes > bricks > tools > Files_To_List” brick.
In case of the ReduceNode brick:
Validate the default node parameters (just click on OK button). The ReduceNode appears in the pipeline editor.
Connect the
outputsplug of the ReduceNode to thefunc_filesplug of the Bold_spatial_preprocessing1 node.Export the
input_0plug of the ReduceNode (right click on theinput_0plug then select export plug), renamed asfunc_files(for clarity).
In case of the Files_To_List brick:
Connect the
file_listplug of the Files_To_List node to thefunc_filesplug of the Bold_spatial_preprocessing1 node.Export the
file1plug of the Files_To_List node (right click on thefile1plug then select export plug), renamed asfunc_files(for clarity).
Export all unconnected plugs of the Bold_spatial_preprocessing1 node (right click on the node then select “export all unconnected plugs”)
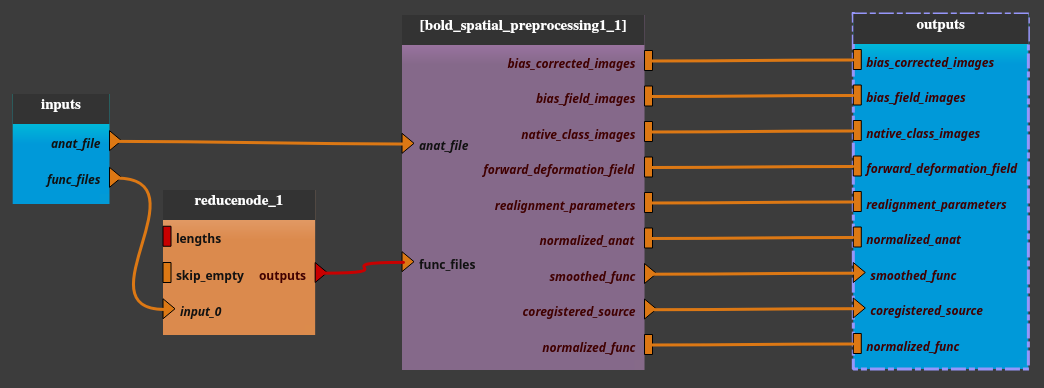
Check on the iterate pipeline button.
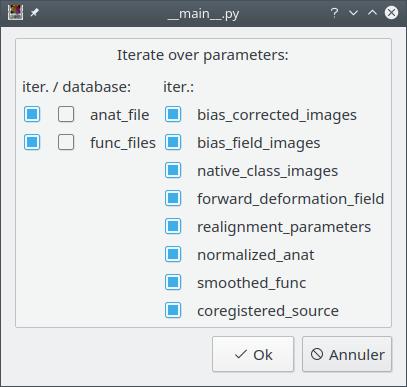
A dialog pops up and displays all the pipeline parameters. The user can choose which ones will be iterated (by default, all). It if’s OK, then just click “OK”.
The pipeline (or process) will now be changed into an iterative pipeline, with an iterative node. The former pipeline is now inside the iterative node.
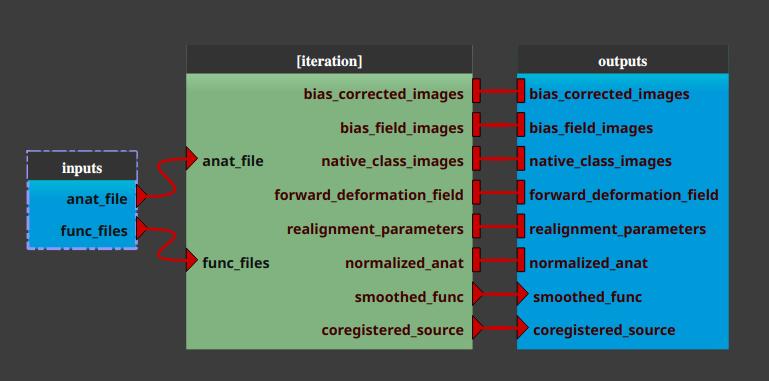
Select the
inputsnodeClick the “Filter” button for the
anat filesparameter, and select the files (anatomical MRIs) we wish to extract the brain from.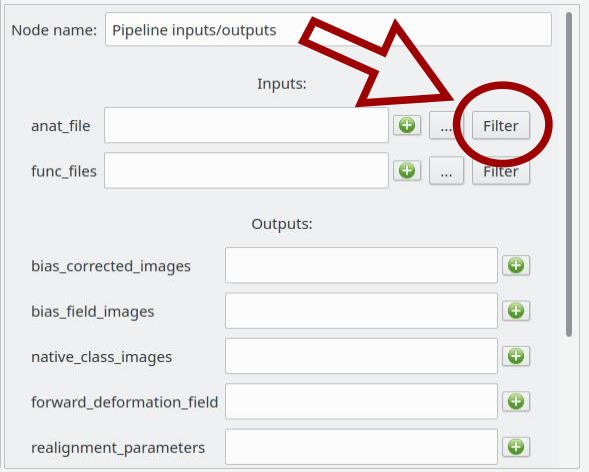
Similarly, click on the “Filter” button for the
func_filesparameter and select the same number of functional files.
Warning
In regular iterative pipeline iteration mode, check that anatomical and corresponding functional files are in the same order… The database filters do not ensure that and do not allow to specify any order…
Click on “Run pipeline”.
Via Input_Filter brick/process¶
Input_Filters are filters applied between the database and the input of a pipeline (or a brick/process). The Input_Filter brick/process is provided in the mia_processes package, since version 1.1.1. The mia_processes package is available from the Cheese Shop.
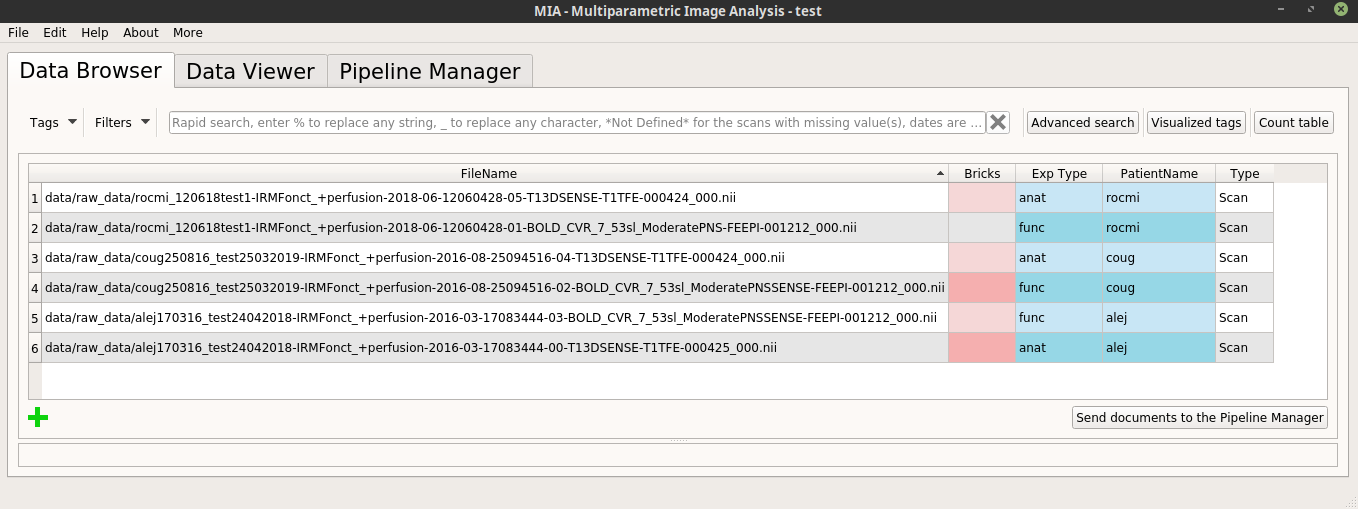
In the following, we will use a database with the Exp Type and PatientName tags correctly filled in, for example:
Without use of the iteration table¶
Starting with a new, empty pipeline tab in the Pipeline Manager:
Add the pipeline mia_processes > pipelines > preprocess > Bold_spatial_preprocessing1 to the pipeline editor.
Check on the iterate pipeline button.
A dialog pops up and displays all the pipeline parameters. In addition to the previous example, also check the second button (for “database”) on each input parameter. Click on the OK button.
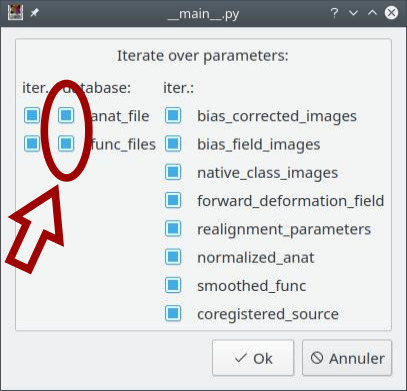
The pipeline (or process) will now be changed into an iterative pipeline, with an iterative node, and two Input_Filters nodes (anat_file_filter and func_files_filter). The former pipeline is now inside the iterative node.
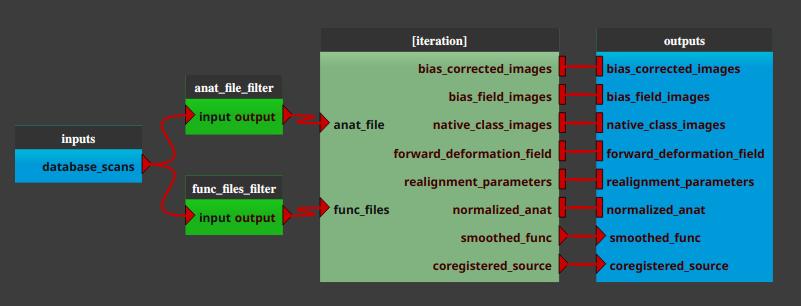
Right-click on the
anat_file_filternode, and select “Open filter”. In the filter pop-up, modify the filter to apply to select the wanted anatomical files.Here is an example where we select all the anatomical images excluding the patient “alej”:
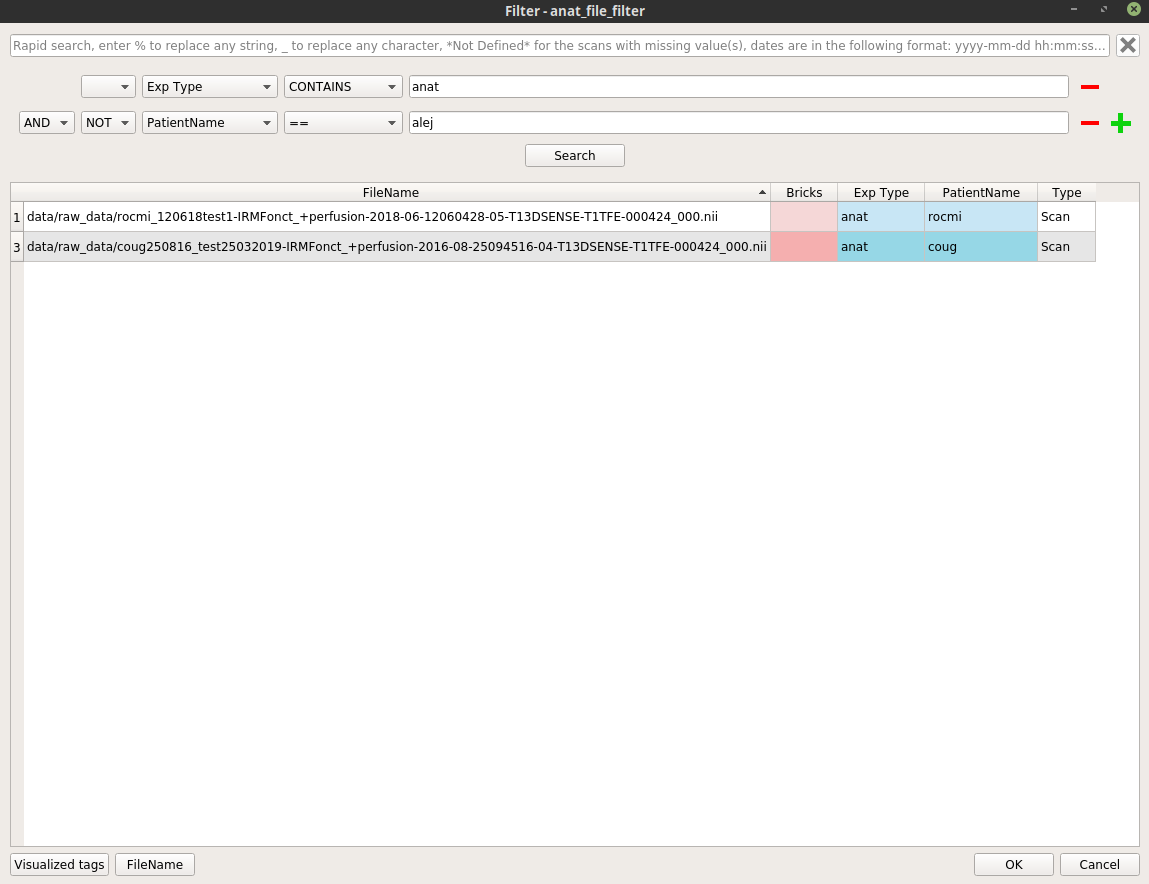
Similarly, right-click on the
func_files_filternode, and select “Open filter”. In the filter pop-up, modify the filter to apply to select the wanted functional files.Here is an example where we select all the functional images excluding the patient “alej”:
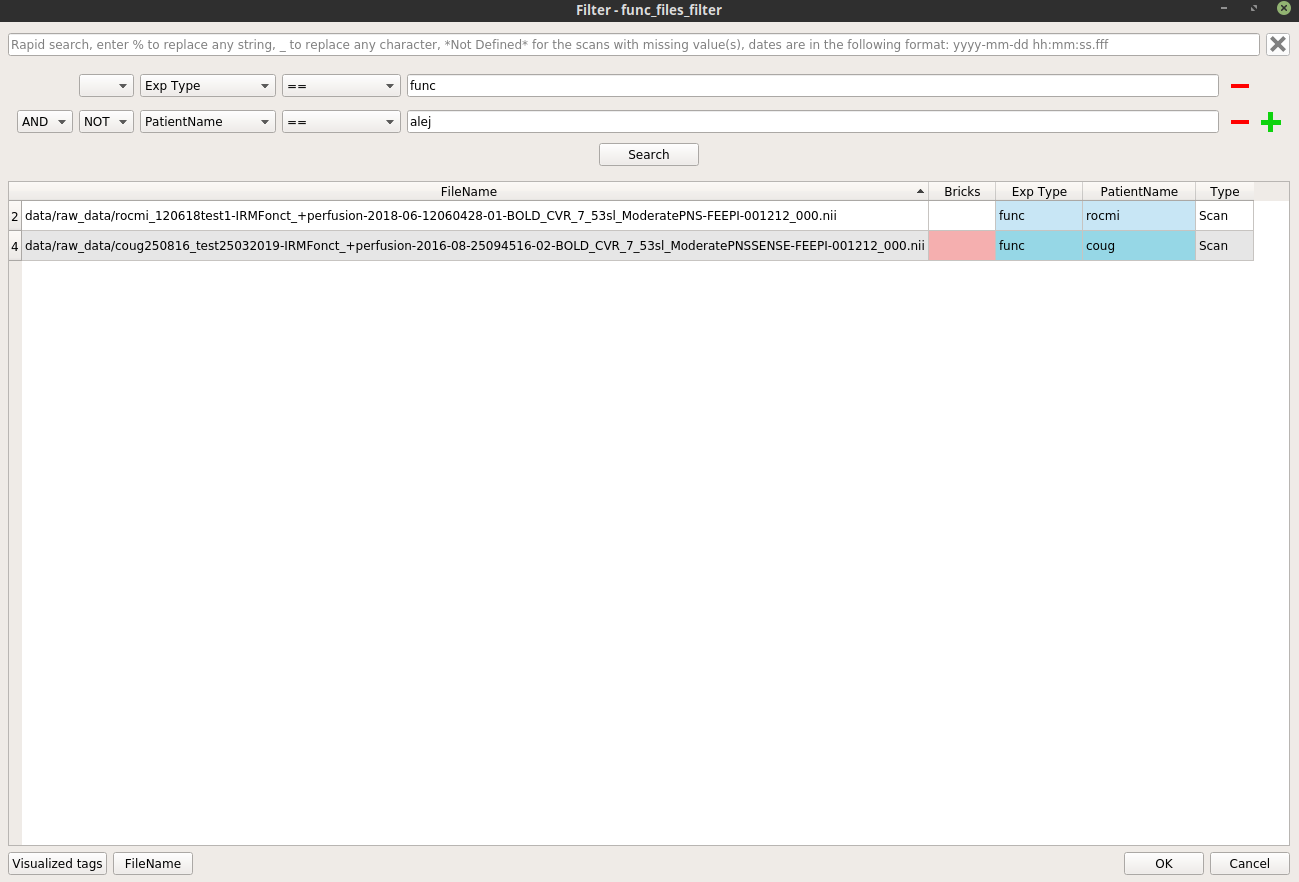
Warning
In via Input_Filter (without use of the iteration table) iteration mode, check that anatomical and corresponding functional files are in the same order… The database filters do not ensure that and do not allow to specify any order…
Click on “Run pipeline”.
With use of the iteration table¶
Follow the same procedure as for the first two points of the via Input_Filter (without use of the iteration table) iteration mode.
Right-click on each Input_filter process and select “Open Filter”. In the filter pop-up window, change the filter to be applied to select all anatomical images for the anat_file input and all functional images for the func_files input.
For example, for the anat_file_filter node, set “Exp Type == anat” (or “Exp Type CONTAINS anat”) in the advanced search field and for the func_files_filter node, set “Exp Type == “func” (or “Exp Type CONTAINS func”) in the advanced search field.
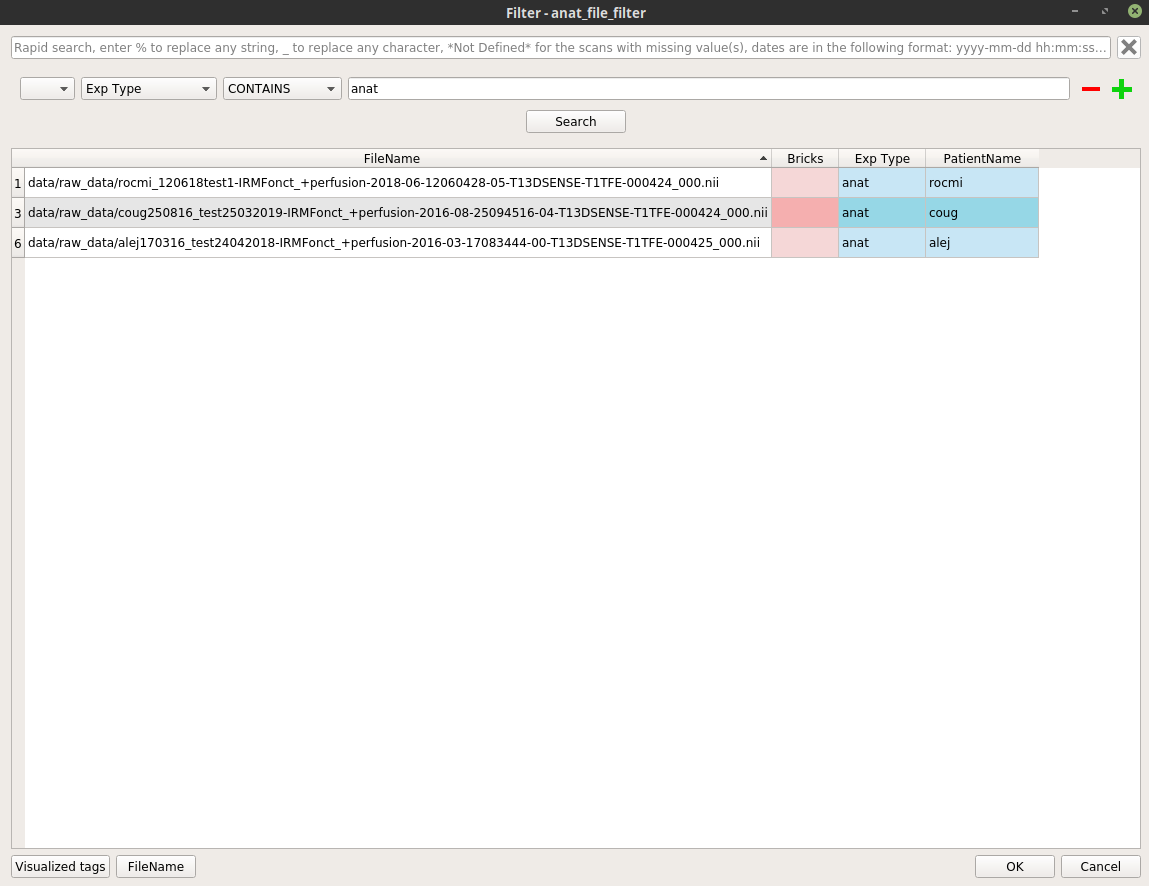
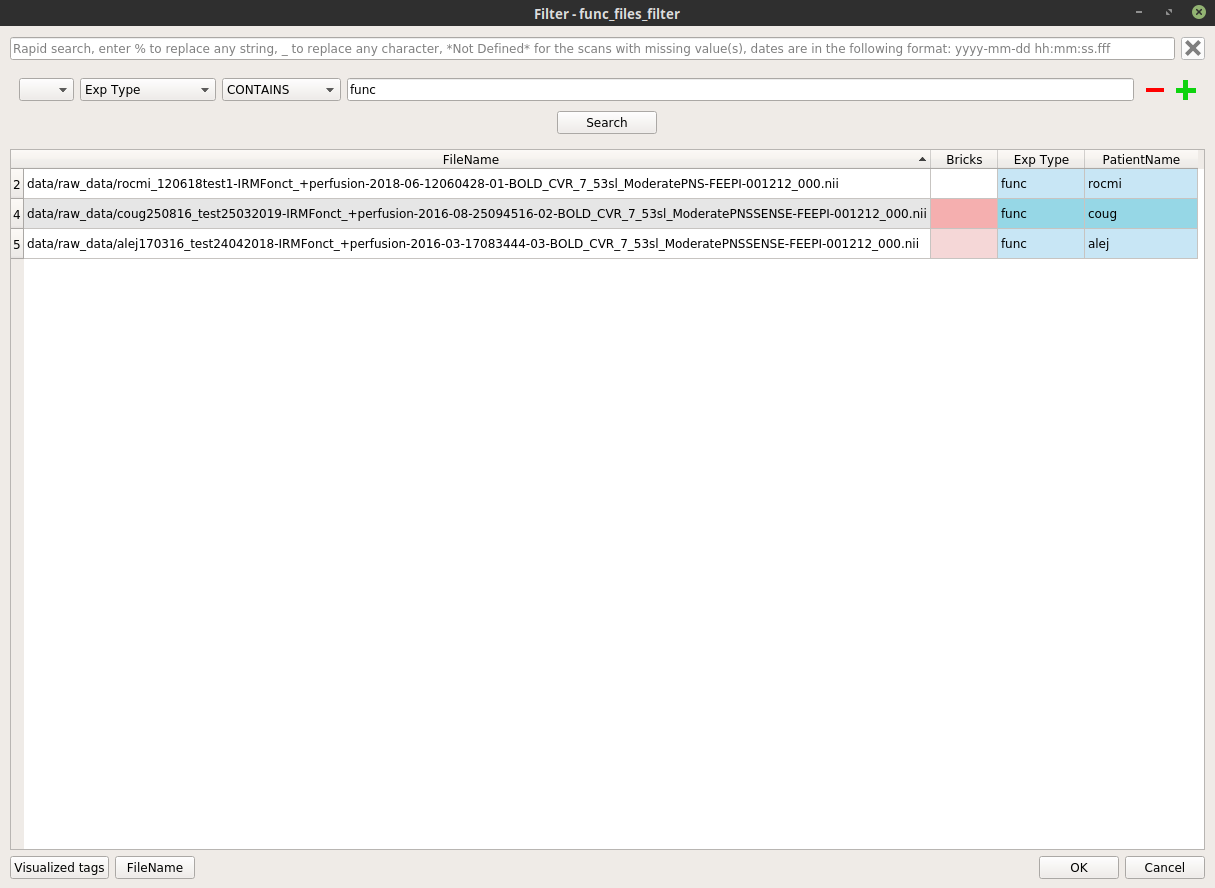
Set up the iteration table:
In the iteration section (top right of the pipeline manager tab), click on the “iterate over” feature (“Select” button). A dialog pops up and displays all the tags in the current project. Check the tag on which the pipeline will be iterated, a good choice could be here the “PatientName” tag.
So below the “iterate over” part there is now a “PatientName” part (in place of “select a tag”, before).
The first button on this “PatientName” part is a Combobox where it is possible to see all the values of the selected tags used to iterate.
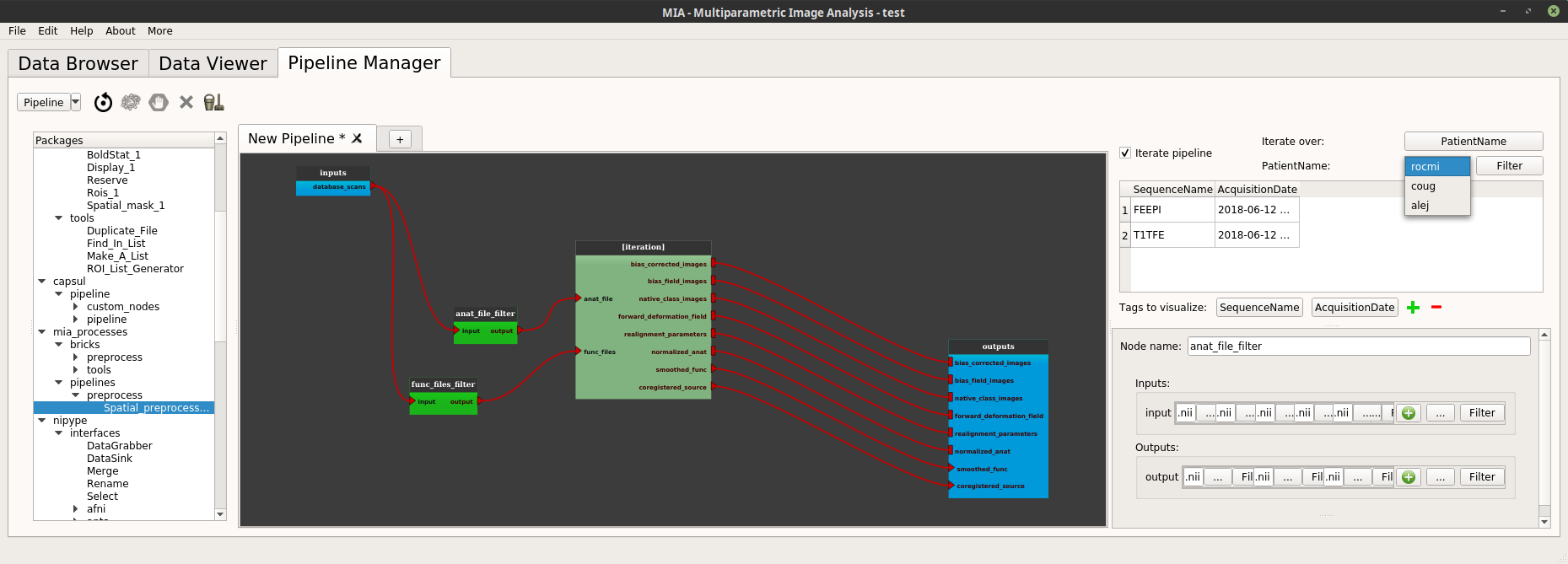
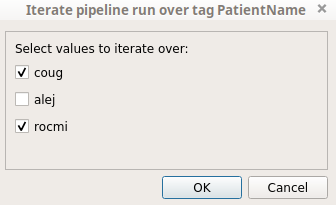
It is possible to change the values used for the iteration by clicking on the next “Filter” button. In the example below we only want to iterate on the “alej” and “rocmi” patients.
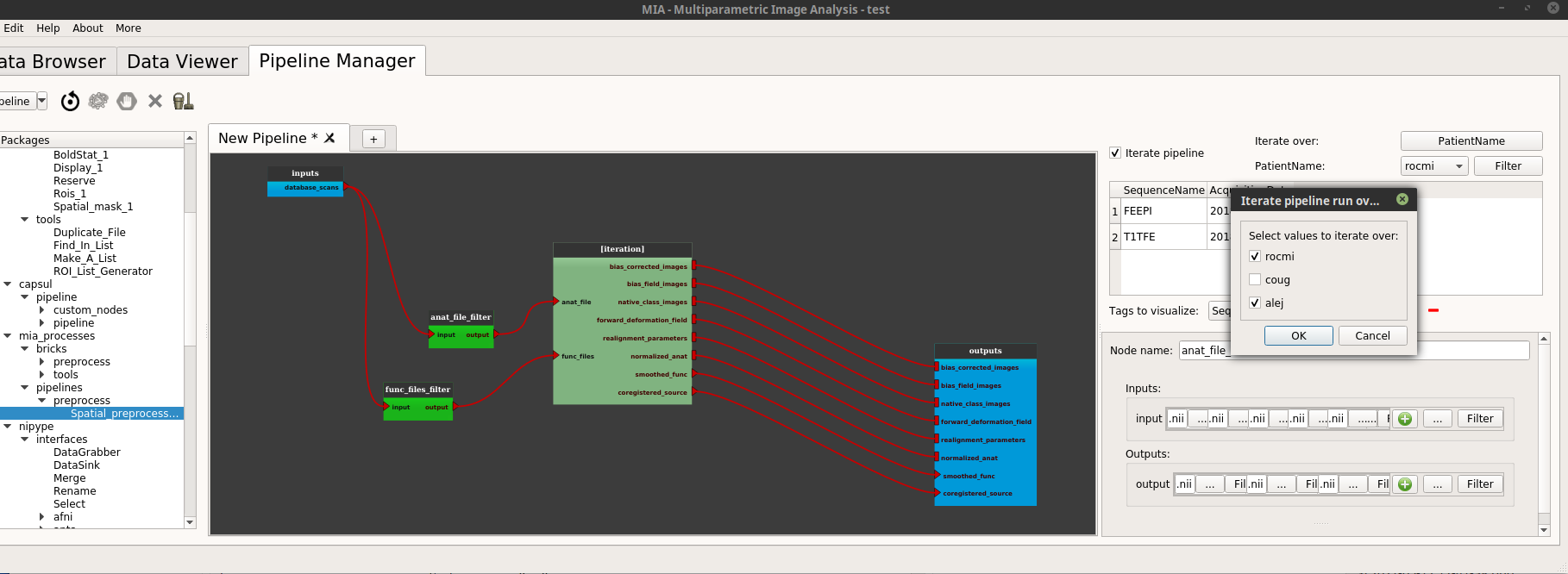
Click on “Run pipeline”.
The iteration table¶
The iteration table is a tool used to handle pipeline iteration and is located on the top right of the Pipeline Manager tab. An iteration can only be made over one tag (e.g. a pipeline in run for each “Patient” value in the database).
The iteration table is composed of several components that are described below in this tutorial.
Please, read the “Pipeline iteration” chapter of the “A pipeline example with Populse_MIA’s” page, in order to have a complete vision of how to use iteration.
How to use the iteration table¶
Assume that the current project contains several patients, so several “PatientName” tag values (the values for the PatientName” tag can be changed manually):
Select which tag to iterate the pipeline on by clicking on the “Select” push button and select the “PatientName” tag. The push button then takes the name of the chosen tag (here PatientName).
- We can visualise for each “PatientName” value which documents are associated thanks to the combo box beside the “Filter” button.
The displayed tags are by default “SequenceName” and “AcquisitionDate” but can be changed at the bottom of the window by clicking on the push buttons, next to “Tags to visualize:”.
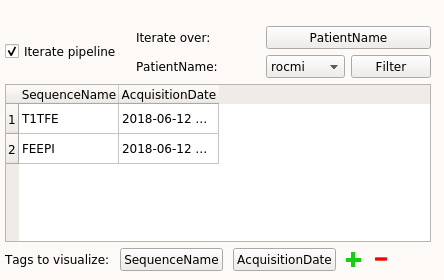
It is possible to choose on which values of the chosen tag we want to iterate the pipeline by clicking on the “Filter” button. Indeed, when the “Filter” button is clicked, a pop-up is displayed to allow us to choose on which values to iterate the pipeline. In the following example we will iterate only on the “coug” and “rocmi” values: