Workflow creation API¶
The workflows are created using the soma_workflow.client API. This page presents the documentation of the Workflow, Job, FileTransfer and SharedResourcePath classes.
See also
Examples for a quick start.
Workflow¶
- class client.Workflow(jobs, dependencies=None, root_group=None, disposal_timeout=168, user_storage=None, name=None, env={}, env_builder_code=None, param_links=None, native_specification=None)[source]¶
Workflow representation.
- name¶
Name of the workflow which will be displayed in the GUI. Default: workflow_id once submitted
- Type:
string
- dependencies¶
Dependencies between the jobs of the workflow. If a job_a needs to be executed before a job_b can run: the tuple (job_a, job_b) must be added to the workflow dependencies. job_a and job_b must belong to workflow.jobs.
In Soma-Workflow 2.7 or higher, dependencies may use groups. In this case, dependencies are replaced internally to setup the groups jobs dependencies. 2 additional barrier jobs (see BarrierJob) are used for each group.
- root_group¶
Recursive description of the workflow hierarchical structure. For displaying purpose only.
Note
root_group is only used to display nicely the workflow in the GUI. It does not have any impact on the workflow execution.
If root_group is not set, all the jobs of the workflow will be displayed at the root level in the GUI tree view.
- Type:
sequence of Job and/or Group
- user_storage¶
For the user needs, any small and picklable object can be stored here.
- Type:
picklable object
- env¶
Environment variables to use when the job gets executed. The workflow- level env variables are set to all jobs.
- Type:
dict(string, string)
- env_builder_code¶
python source code. This code will be executed from the engine, on server side, but not in a processing node (in a separate python process in order not to pollute the engine process) when a workflow is starting. The code should print on the standard output a json dictionary of environment variables, which will be set into all jobs, in addition to the env variable above.
- Type:
string
- param_links¶
New in 3.1. Job parameters links. Links are in the following shape:
dest_job: {dest_param: [(source_job, param, <function>), ...]}
Links are used to get output values from jobs which have completed their run, and to set them into downstream jobs inputs. This system allows “dynamic outputs” in workflows. The optional function item is the name of a function that will be called to transform values from the source to the destination of the link at runtime. It is basically a string “module.function”, or a tuple for passing some arguments (as in partial): (“module.function”, 12, “param”). The function is called with additional arguments: parameter name, parameter value, destination parameter name, destination parameter current value. The destination parameter value is typically used to build / update a list in the destination job from a series of values in source jobs.
See Parameters link functions for details.
- Type:
- native_specification¶
Some specific option/function of the computing resource you want to use might not be available among the list of Soma-workflow Job attributes. Use the native specification attribute to use these specific functionalities. If a native_specification is defined here, the configured native specification will be ignored (documentation configuration item: NATIVE_SPECIFICATION).
Example: Specification of a job walltime and more:
using a PBS cluster: native_specification=”-l walltime=10:00:00,pmem=16gb”
using a SGE cluster: native_specification=”-l h_rt=10:00:00”
- using a SLURM cluster:
native_specification=[”–mem=20g”, “-time=2-00:00:00”]
- Type:
string or list
In Soma-Workflow 3.1, some “jobs outputs” have been added. This concept is somewhat contradictory with the commandline execution model, which basically does not produce outputs other than files. To handle this, jobs which actually produce “outputs” (names parameters with output values) should write a JSON file containing the output values dictionary.
Output values are then read by Soma-Workflow, and values are set in the downstream jobs which depend on these values.
For this, “parameters links” have been added, to tell Soma-Workflow which input parameters should be replaced by output parameter values from an upstream job.
param_links is an (optional) dict which specifies these links:
{dest_job: {dest_param: [(source_job, param, <function>), ...]}}
Such links de facto define new jobs dependencies, which are added to the dependencies manually specified.
The optional function item is the name of a function that will be called to transform values from the source to the destination of the link at runtime. It is basically a string “module.function”, or a tuple for passing some arguments (as in partial): (“module.function”, 12, “param”). The function is called with additional arguments: parameter name, parameter value, destination parameter name, destination parameter current value. The destination parameter value is typically used to build / update a list in the destination job from a series of values in source jobs.
- Parameters:
jobs
dependencies
root_group
disposal_timeout
user_storage
name
env
env_builder_code
param_links
native_specification
- add_dependencies_from_links()[source]¶
Process parameters links and add missing jobs dependencies accordingly
- add_workflow(workflow, as_group=None)[source]¶
Concatenates a workflow into the current one.
- Parameters:
workflow (Workflow) – workflow to be added to self
as_group (string (optional)) – if specified, the workflow will be added as a group with the given name
- Returns:
if as_group is specified, the group created for the sub-workflow will be returned, otherwise the function returns None.
- Return type:
group or None
Group¶
- class client.Group(elements, name, user_storage=None)[source]¶
Hierarchical structure of a workflow.
- elements: sequence of Job and/or Group
The elements (Job or Group) belonging to the group.
- name: string
Name of the Group which will be displayed in the GUI.
- user_storage: picklable object
For the user needs, any small and picklable object can be stored here.
@type elements: sequence of Job and/or Group @param elements: the elements belonging to the group @type name: string @param name: name of the group
Job¶
- class client_types.Job(command, referenced_input_files=None, referenced_output_files=None, stdin=None, join_stderrout=False, disposal_timeout=168, name=None, stdout_file=None, stderr_file=None, working_directory=None, parallel_job_info=None, priority=0, native_specification=None, user_storage=None, env=None, param_dict=None, use_input_params_file=False, has_outputs=False, input_params_file=None, output_params_file=None, configuration={})[source]¶
Job representation.
Note
The command is the only argument required to create a Job. It is also useful to fill the job name for the workflow display in the GUI.
Parallel jobs
When a job is designed to run on multiple processors, cluster managements systems normally do the necessary work to run or duplicate the job processes on multiple computing nodes. There are basically 3 classical ways to do it:
use MPI (whatever implementation): job commands are run through a launcher program (
mpirun) which will run the processes and establish inter-process communications.use OpenMP: this threading-based system allows to use several cores on the same computing node (using shared memory). The OpenMP allows to use the required nuber of threads.
manual threading or forking (“native” mode).
In all cases one job runs on several processors/cores. The MPI variant additionally allows to run the same job on several computing nodes (which do not share memory), the others should run on the same node (as far as I know - I’m not an expert of OpenMP). The job specifications should then precise which kind of parallelism they are using, the number of nodes the job should run on, and the number of CPU cores which should be allocated on each node. Thus the parallel_job_info variable of a job is a dictionary giving these 3 information, under the respective keys config_name, nodes_number and cpu_per_node. In OpenMP and native modes, the nodes_number should be 1.
- command¶
The command to execute. It can not be empty. In case of a shared file system the command is a sequence of string.
In the other cases, the FileTransfer, SharedResourcePath, and TemporaryPath objects will be replaced by the appropriate path before the job execution.
The tuples (FileTransfer, relative_path) can be used to refer to a file in a transfered directory.
The sequences of FileTransfer, SharedResourcePath or tuple (FileTransfer, relative_path) will be replaced by the string “[‘path1’, ‘path2’, ‘path3’]” before the job execution. The FileTransfer, SharedResourcePath or tuple (FileTransfer, relative_path) are replaced by the appropriate path inside the sequence.
- Type:
sequence of string or/and FileTransfer or/and SharedResourcePath or/and TemporaryPath or/and tuple (FileTransfer, relative_path) or/and sequence of FileTransfer or/and sequence of SharedResourcePath or/and sequence of tuple (FileTransfer, relative_path)
- name¶
Name of the Job which will be displayed in the GUI
- Type:
string
- referenced_input_files¶
List of the FileTransfer which are input of the Job. In other words, FileTransfer which are requiered by the Job to run. It includes the stdin if you use one.
- Type:
sequence of SpecialPath (FileTransfer, TemporaryPath…)
- referenced_output_files¶
List of the FileTransfer which are output of the Job. In other words, the FileTransfer which will be created or modified by the Job.
- Type:
sequence of SpecialPath (FileTransfer, TemporaryPath…)
- stdin¶
Path to the file which will be read as input stream by the Job.
- Type:
string or FileTransfer or SharedResourcePath
- join_stderrout¶
Specifies whether the error stream should be mixed with the output stream.
- Type:
boolean
- stdout_file¶
Path of the file where the standard output stream of the job will be redirected.
- Type:
string or FileTransfer or SharedResourcePath
- stderr_file¶
Path of the file where the standard error stream of the job will be redirected.
Note
Set stdout_file and stderr_file only if you need to redirect the standard output to a specific file. Indeed, even if they are not set the standard outputs will always be available through the WorklfowController API.
- Type:
string or FileTransfer or SharedResourcePath
- working_directory¶
Path of the directory where the job will be executed. The working directory is useful if your Job uses relative file path for example.
- Type:
string or FileTransfer or SharedResourcePath
- priority¶
Job priority: 0 = low priority. If several Jobs are ready to run at the same time the jobs with higher priority will be submitted first.
- Type:
- native_specification¶
Some specific option/function of the computing resource you want to use might not be available among the list of Soma-workflow Job attributes. Use the native specification attribute to use these specific functionalities. If a native_specification is defined here, the configured native specification will be ignored (documentation configuration item: NATIVE_SPECIFICATION).
Example: Specification of a job walltime and more:
using a PBS cluster: native_specification=”-l walltime=10:00:00,pmem=16gb”
using a SGE cluster: native_specification=”-l h_rt=10:00:00”
- using a SLURM cluster:
native_specification=[”–mem=20g”, “-time=2-00:00:00”]
- Type:
string or list
- parallel_job_info¶
The parallel job information must be set if the Job is parallel (ie. made to run on several CPU). The parallel job information is a dict, with the following supported items:
config_name: name of the configuration (native, MPI, OpenMP)
nodes_number: number of computing nodes used by the Job,
cpu_per_node: number of CPU or cores needed for each node
The configuration name is the type of parallel Job. Example: MPI or OpenMP.
Warning
The computing resources must be configured explicitly to use this feature.
- Type:
- user_storage¶
Should have been any small and picklable object for user need but was never fully implemented. This parameter is simply ignored.
- Type:
picklable object
- param_dict¶
New in 3.1. Optional dictionary for job “parameters values”. In case of dynamic outputs from a job, downstream jobjs values have to be set accordingly during the workflow execution. Thus we must be able to know how to replace the parameters values in the commandline. To do so, jobs should provide commandlines not with builtin values, but with replacement strings, and a dict of parameters with names:
command = ['cp', '%(source)s', '%(dest)s'] param_dict = {'source': '/data/file1.txt', 'dest': '/data/file2.txt'}
Parameters names can be linked in the workflow to some other jobs outputs.
- Type:
- use_input_params_file¶
if True, input parameters from the param_dict will not be passed using substitutions in the commandline, but through a JSON file.
- Type:
- has_outputs¶
New in 3.1. Set if the job will write a special JSON file which contains output parameters values, when the job is a process with outputs.
- Type:
- input_params_file¶
Path to the file which will contain input parameters of the job.
- Type:
string or FileTransfer or SharedResourcePath
- output_params_file¶
Path to the file which will be written for output parameters of the job.
- Type:
string or FileTransfer or SharedResourcePath
- commandline_repl(command)[source]¶
Get “processed” commandline list. Each element in the commandline list which contains a replacement string in the shame %(var)s is replaced using the param_dict values.
- classmethod from_dict(d, tr_from_ids, srp_from_ids, tmp_from_ids, opt_from_ids)[source]¶
d dictionary
tr_from_id id -> FileTransfer
srp_from_id id -> SharedResourcePath
tmp_from_ids id -> TemporaryPath
opt_from_ids id -> OptionPath
- to_dict(id_generator, transfer_ids, shared_res_path_id, tmp_ids, opt_ids)[source]¶
id_generator IdGenerator
- transfer_ids dict: client.FileTransfer -> int
This dictonary will be modified.
- shared_res_path_id dict: client.SharedResourcePath -> int
This dictonary will be modified.
tmp_ids dict: client.TemporaryPath -> int
opt_ids dict: client.OptionPath -> int
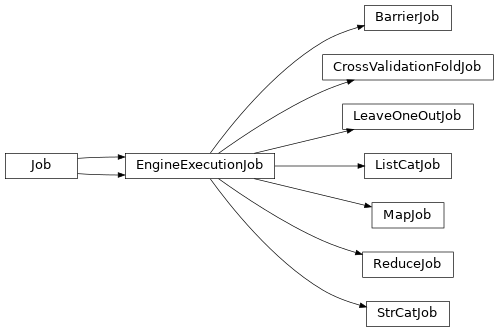
- class client_types.EngineExecutionJob(command, referenced_input_files=None, referenced_output_files=None, stdin=None, join_stderrout=False, disposal_timeout=168, name=None, stdout_file=None, stderr_file=None, working_directory=None, parallel_job_info=None, priority=0, native_specification=None, user_storage=None, env=None, param_dict=None, use_input_params_file=False, has_outputs=False, input_params_file=None, output_params_file=None, configuration={})[source]¶
EngineExecutionJob: a lightweight job which will not run as a “real” job, but as a python function, on the engine server side.
Such jobs are meant to perform fast, simple operations on their inputs in order to produce modified inputs for other downstream jobs, such as string substituitons, lists manipulations, etc. As they will run in the engine process (generally the jobs submission machine) they should not perform expensive processing (CPU or memory-consuming).
They are an alternative to link functions in Workflows.
The only method an EngineExecutionJob defines is
engine_execution(), which will be able to use its parameters dict (as defined in its param_dict as any other job), and will return an output parameters dict.Warning: the
engine_execution()is actually a class method, not a regular instance method. The reason for this is that it will be used with anEngineJobinstance, which inheritsJob, but not the exact subclass. Thus in the method,selfis not a real instance of the class.The default implementation just passes its input parameters as outputs in order to allow later jobs to reuse their parameters. Subclasses define their own
engine_execution()methods.See Engine execution jobs for more details.
- class client_types.BarrierJob(command=[], referenced_input_files=None, referenced_output_files=None, name=None)[source]¶
Barrier job: it is a “fake” job which does nothing (and will not become a real job on the DRMS) but has dependencies. It may be used to make a dependencies hub, to avoid too many dependencies with fully connected jobs sets.
BarrierJob is implemented as an EngineExecutionJob, and just differs in its name, as its
engine_execution()method does nothing.- Ex:
(Job1, Job2, Job3) should be all connected to (Job4, Job5, Job6) needs 3*3 = 9 (N^2) dependencies. With a barrier:
Job1 Job4 \ / Job2 -- Barrier -- Job5 / \. Job3 Job6
needs 6 (2*N).
BarrierJob constructor accepts only a subset of Job constructor parameter:
referenced_input_files
referenced_output_files
name
- classmethod from_dict(d, tr_from_ids, srp_from_ids, tmp_from_ids, opt_from_ids)[source]¶
d dictionary
tr_from_id id -> FileTransfer
srp_from_id id -> SharedResourcePath
tmp_from_ids id -> TemporaryPath
opt_from_ids id -> OptionPath
- to_dict(id_generator, transfer_ids, shared_res_path_id, tmp_ids, opt_ids)[source]¶
id_generator IdGenerator
- transfer_ids dict: client.FileTransfer -> int
This dictonary will be modified.
- shared_res_path_id dict: client.SharedResourcePath -> int
This dictonary will be modified.
tmp_ids dict: client.TemporaryPath -> int
opt_ids dict: client.OptionPath -> int
- class custom_jobs.MapJob(command=[], referenced_input_files=None, referenced_output_files=None, name='map', param_dict=None, **kwargs)[source]¶
Map job: converts lists into series of single items. Typically an input named
inputsis a list of items. The job will separate items and output each of them as an output parameter. The i-th item will be output asoutput_<i>by default. The inputs / outputs names can be customized using the named parametersinput_namesandoutput_names. Several lists can be split in the same job. The job will also output alengthsparameter which will contain the input lists lengths. This lengths can typically be input in reduce jobs to perform the reverse operation (seeReduceJob).input_namesis a list of input parameters names, each being a list to
be split. The default is
['inputs']*output_namesis a list of patterns used to build output parameters names. Each item is a string containing a substitution pattern"%d"which will be replaced with a number. The default is['output_%d']. Each pattern will be used to replace items from the corresponding input in the same order. Thusinput_namesandoutput_namesshould be the same length. * all other parameters given inparam_dictare passed to the output dictionary of the job, so that the job acts as aBarrierJobfor parameters which are not “mapped”.
- class custom_jobs.ReduceJob(command=[], referenced_input_files=None, referenced_output_files=None, name='reduce', param_dict=None, **kwargs)[source]¶
Reduce job: converts series of inputs into lists. Typically a series of inputs named
input_0..input_<n>will be output as a single list namedoutputs.Several input series can be handled by the job, and input names can be customized.
The numbers of inputs for each series is given as the
lengthsinput
parameter. It is typically linked from the output of a
MapJob. * Input parameters names patterns are given as theinput_namesparameter. It is a list of patterns, each containing a%d``pattern for the input number. The defaut value is ``['input_%d']. * Output parameters names are given as theoutput_namesparameter. The default is['outputs']. * all other parameters given inparam_dictare passed to the output dictionary of the job, so that the job acts as aBarrierJobfor parameters which are not “reduced”.
- class custom_jobs.ListCatJob(command=[], referenced_input_files=None, referenced_output_files=None, name='list_cat', param_dict=None, **kwargs)[source]¶
Concatenates several lists into a single list
The input lists should be specified as the
inputsparameter (a list of lists, thus). The output parameteroutputswill be assigned the concatenated list.
- class custom_jobs.StrCatJob(command=[], referenced_input_files=None, referenced_output_files=None, name='strcat', param_dict=None, **kwargs)[source]¶
Concatenates inputs into a string
Inputs listed in
input_namesare concatenated into an output string. Inputs may be strings or lists of strings. Listes are also concatenated into a string. The output parameter is given as theoutput_nameparameter, if given, and defaults to `` output`` otherwise.input_namesis optional and defaults toinputs(thus by default the job expects a single list).
- class custom_jobs.LeaveOneOutJob(command=[], referenced_input_files=None, referenced_output_files=None, name='leave_one_out', param_dict=None, **kwargs)[source]¶
Removes an element from an input list, outputs it on a single separate output.
The input list should be specified as the
inputsparameter, and the item index asindex. The output parameterstrainandtestwill be assigned the modified list and extracted element, respectively.
- class custom_jobs.CrossValidationFoldJob(command=[], referenced_input_files=None, referenced_output_files=None, name='cross_validation', param_dict=None, **kwargs)[source]¶
Separates an input list into folds, one (larger) for training, one (smaller) for testing.
The input list
inputsis separated into folds. The number of folds should be specified as thenfoldsparameter, the fold number asfold. Outputs aretrain` and ``testparameters.
FileTransfer¶
- class client.FileTransfer(is_input, client_path=None, disposal_timeout=168, name=None, client_paths=None)[source]¶
File/directory transfer representation
Note
FileTransfers objects are only required if the user and computing resources have a separate file system.
- client_path: string
Path of the file or directory on the user’s file system.
- initial_status: constants.FILES_DO_NOT_EXIST or constants.FILES_ON_CLIENT
constants.FILES_ON_CLIENT for workflow input files The file(s) will need to be transfered on the computing resource side
constants.FILES_DO_NOT_EXIST for workflow output files The file(s) will be created by a job on the computing resource side.
- client_paths: sequence of string
Sequence of path. Files to transfer if the FileTransfers concerns a file series or if the file format involves several associated files or directories (see the note below).
- name: string
Name of the FileTransfer which will be displayed in the GUI. Default: client_path + “transfer”
When a file is transfered via a FileTransfer, the Job it is used in has to be built using the FileTransfer object in place of the file name in the command list. The FileTransfer object has also to be on the referenced_input_files or referenced_output_files lists in Job constructor.
Note
Use client_paths if the transfer involves several associated files and/or directories. Examples:
file series
file format associating several file and/or directories (ex: a SPM images are stored in 2 associated files: .img and .hdr) In this case, set client_path to one the files (ex: .img) and client_paths contains all the files (ex: .img and .hdr files)
In other cases (1 file or 1 directory) the client_paths must be set to None.
When client_paths is not None, the server-side handling of paths is different: the server directory is used istead of files. This has slight consequences on the behaviour of the workflow:
in soma-workflow 2.6 and earlier, the commandline will be using the directory instead of a file name, which is often not what you expect.
in soma-workflow 2.7 and later, the commandline will be using the main file name (client_path) translated to the server location. This is more probably what is expected.
in any case it is possible to specify the commandline path using a tuple as commandline argument:
myfile = FileTransfer(is_input=True, client_path='/home/bubu/plof.nii', client_paths=['/home/bubu/plof.nii', '/home/bubu/plof.nii.minf']) # job1 will work with SWF >= 2.7, not in 2.6 job1 = Job(command=['AimsFileInfo', myfile], referenced_input_files=[myfile]) # job2 will use <engine_path>/plof.nii as input job2 = Job(command=['AimsFileInfo', (myfile, 'plof.nii')], referenced_input_files=[myfile]))
- Parameters:
is_input (bool) – specifies if the files have to be transferred from the client before job execution, or back to the client after execution.
client_path (string) – main file name
disposal_timeout (int (optional)) – default: 168
name (string (optional)) – name displayed in the GUI
client_paths (list (optional)) – when several files are involved
TemporaryPath¶
- class client.TemporaryPath(is_directory=False, disposal_timeout=168, name=None, suffix='')[source]¶
Temporary file representation. This temporary file will never exist on client side: its filename will be created on server side, used during the workflow execution, and removed when not used any longer.
Dynamic output parameters values in Soma-Workflow¶
This is a new feature in Soma-Workflow 3.1.
It allows jobs to produce “output parameters”, which will in turn be used as inputs in downstream jobs.
As jobs are basically commandlines, they normally cannot have outputs other than files. Thus we manage the output parameters by allowing a job to write an additional file (JSON format) containing a dictionary of output parameters and values.
Such a job will be “marked” as producing outputs (Job variable has_outputs, and before running it, Soma-Workflow will set the environment variable SOMAWF_OUTPUT_PARAMS for it, with an output filename value. The job should write the output file at this location. The output parameters file will be read by Soma-Workflow once the job has successfully finished.
Then when running later jobs, their input values will be changed accordingly. To allow this, we need a few things:
Using dynamic output parameters¶
such jobs should declare a dictionary of input parameters (Job variable
param_dict)the workflow should define some “parameters links” between jobs in order to connect output parameters values from one job to the input parameters values of downstream jobs: Workflow variable
param_linnks.The input parameters dictionary of a job has to be used to re-build its commandline properly after their values have changed. To do so, the commandline arguments of such jobs can contain some substitution strings in the python style
"%(param)s", whereparamis a named parameter in the dictionary.
To put things togethr in an example:
from soma_workflow.client import Job, Workflow, WorkflowController
# workflow definition
job1 = Job(
command=['my_program', '%(in1)s'],
name='job1:cp',
param_dict={'in1': '/tmp/input_file'},
has_outputs=True)
job2 = Job(
command=['cat', '%(in1)s'],
name='job2:cat',
param_dict={'in1': 'undefined'})
workflow = Workflow(jobs=[job1, job2], name='test_workflow',
param_links={job2: {'in1': [(job1, 'out1')]}})
# running it is the classical way
# (or using soma_workflow_gui)
wc = WorkflowController()
wf_id = wc.submit_workflow(workflow)
wc.wait_workflow(wf_id)
Here, job1 will run a program, my_program which will do its job, and write the output parameters file. The param_dict in job1 is not necessary here, since its parameters values will not change according to upstream operations, but if we want to allow job classes to be used in such “dynamic” workflows, we rather have to get used to name all their parameters.
job2 input parameter in1 will get its value from job1 ouput named out1. This is specified via the workflow param_links which is a dict associating to a destination job a set of parameters values, each coming from another job’s parameter. For instance:
param_links = {
dest_job1: {
'dest_param1': [(src_job1, 'src_output_param1')],
'dest_param2': [(src_job2, 'src_output_param2')],
},
dest_job2: {
'dest_param3': [(src_job3, 'src_output_param3')],
'dest_param4': [(src_job4, 'src_output_param4')],
},
}
Note that param_links in the workflow implicitly add jobs dependencies. These new dependencies are automatically added to the “classical” jobs dependencies, and may completely replace them if parameters links are correctly specified and used all along the workflow.
Now the job1 commandline program, if written in Python language, could look like this:
#!/usr/bin/env python
import os
import shutil
import json
import sys
# we have to write the output parameters values in this file:
output_param_file = os.environ.get('SOMAWF_OUTPUT_PARAMS')
# we impose a "hard-coded" output path, just because our programs
# works that way.
out_file = os.path.expanduser('~/bubulle.txt')
in_file = sys.argv[1] # input given as parameter from the job
# let's say this is the "real" job of my_program
shutil.copy2(in_file, out_file)
# write output parameters (only one, in our case)
if output_param_file:
params = {
'out1': out_file,
}
json.dump(params, open(output_param_file, 'w'))
As you can see, in a “classical” workflow, job2 would not have known which file to print in its cat command. Using this “dynamic” parameters structure, it can work.
Dynamic outputs and file transfers¶
When a file name is an output of a job (the job decides where to write its output file), and this output file should be transfered from the computing resource to the client machine, then a FileTransfer object should be created (as usual), but with some little additional things to setup:
The FileTransfer object should be added both to the
referenced_output_filesparameter of jobs (as usual), and to the named parameters (param_dict) in order to tell how the FileTransfer object should be updated from the output JSON file of the job.The FileTransfer cannot know its paths (both client and server side) before the job runs.
A client path has to be built after the job outputs tells which is the engine path. There is not absolute correct way to build it, it’s a heuristic since we have no reference client directory in the general case.
To help this, we may use an additional job named parameter in the
param_dict:output_directory, which will be used as a basis for client paths building.Otherwise Soma-Workflow will try to guess a client directory from other job parameters. This will not work in all situations.
Ex:
toutp = FileTransfer(False, 'job1_output')
job1 = Job(
command=['my_program', '%(in1)s'],
name='job1:cp',
param_dict={'in1': '/tmp/input_file',
# this is an output FileTransfer param mathcing the
# job ourput json dict
'out1': toutp,
# this is a hint to where to write the client output file
'output_directory': '/tmp'},
has_outputs=True,
referenced_output_files=[toutp])
job2 = swc.Job(
command=[sys.executable, inp, 'job2_run', '%(in1)s'],
name='job2:cat',
param_dict={'in1': toutp},
referenced_input_files=ref_outp)
workflow = swc.Workflow(jobs=[job1, job2], name='test_out_wf',
param_links={job2: {'in1': [(job1, 'out1')]}})
Job input parameters as file¶
When job parameters are specified through a dictionary of named parameters, it is also possible to pass the parameters set as a JSON file, rather than on commandline arguments. This may prove useful when the parameters list is long.
In this situation the job must declare it using the use_input_params_file variable in Job. Then a temporary file will be created before the job is run. The parameters file is a JSON file containing a dictionary. The first level of this dict currently only contains the key "parameters", but will be able to hold job configuration in the future. The parameters sub-dict is the input parameters of the job.
The input parameters fils location is specified through an environment variable: SOMAWF_INPUT_PARAMS, and the job program should read it to get its actual arguments.
Ex:
from soma_workflow.client import Job, Workflow, WorkflowController
# workflow definition
job1 = Job(
command=['my_program', '%(in1)s'],
name='job1:cp',
param_dict={'in1': '/tmp/input_file'},
has_outputs=True)
job3 = Job(
command=['my_cat_program'], # no parameters on the commandline
name='job2:cat',
param_dict={'in1': 'undefined'},
use_input_params_file=True) # tell SWF to write the params file
workflow2 = Workflow(jobs=[job1, job3], name='test_workflow',
param_links={job3: {'in1': [(job1, 'out1')]}})
# running it is the classical way
# (or using soma_workflow_gui)
wc = WorkflowController()
wf_id = wc.submit_workflow(workflow2)
wc.wait_workflow(wf_id)
Here job3 must be modified to make it able to read the parameters file. In this example we call a program named my_cat_program, which, if written in Python language, could look like this:
#!/usr/bin/env python
import os
import json
# get the input pams file location from env variable
param_file = os.environ.get('SOMAWF_INPUT_PARAMS')
# read it
params = json.load(open(param_file))
# now get our specific parameter(s)
in_file = params['parameters']['in1']
# now the "real" job code just prints the file:
print(open(in_file).read())
Parameters link functions¶
To implement some classical schemas such as map/reduce or cross-validation patterns, we need to transform parameters values which are lists into a series of single values, each passed to a job, for instance. To do this, Soma-Workflow allows to specify link functions in param_links. Such functions are called when building a job inputs before it runs (on engine side). Such functions are passed as an additional item in the link tuple, and may be strings (function definition, including module if appropriate), or a tuple containing a string (function definition) and arguments passed to it:
Ex:
param_links = {
dest_job1: {
'dest_param1': [(src_job1, 'src_output_param1',
'link_module.link_function')],
'dest_param2': [(src_job2, 'src_output_param2',
('link_module.link_function', 3))],
},
}
Arguments, if used, are passed in the function as first parameters, and may be used to specify a counter or identifier for the linked job. Functions are then called using 4 additional arguments: source parameter name, source parameter value, destination parameter name, destination parameter current value. The function should return the new destination parameter value. The destination parameter current value is useful in some cases, for instance to build a list from several source links (reduce pattern).
A few functions are directly available in Soma-Workflow, in the module param_link_functions, to help implementing classical algorithmic patterns:
list_to_sequence(), sequence_to_list(), list_all_but_one(), list_cv_train_fold(), list_cv_test_fold().
Custom functions may be used, as long as their module is specified, with the additional constraint that the custom functions modules should be installed on engine side on the computing resource.
Note that this parameters links transformations are the reason why links are lists and not single values: intuitively one may think that a job parameter value is linked from a single job output value, but when dealing with lists, the situatioon may differ: a list can be built from several outputs.
Note
aternative: Engine execution jobs
An alternative to parameters link functions ias also available in Soma-Workflow 3.1 and later: Engine execution jobs. They are more convenient to use in some situations, and less in others, so a workflow developer may choose the implementation he prefers.
A cross-validation pattern example:
# let's say job1 inputs a list and outputs another list, 'outputs'
job1 = Job(
command=['my_program', '%(inputs)s'], name='prepare_inputs',
param_dict={'inputs': ['file1', 'file2', 'file3', 'file4', 'file5']},
has_outputs=True)
# train_jobs are identical train jobs training folds (we use 3 folds)
# they output a single file, 'output'
# test_jobs are identical test jobs testing the test part of each fold
# they also output a single file, 'output'
nfolds = 3
train_jobs = []
test_jobs = []
for fold in range(nfolds):
job_train = Job(
command=['train_model', '%(inputs)s'], name='train_fold%d' % fold,
param_dict={'inputs', []}, has_outputs=True)
train_jobs.append(job_train)
job_test = Job(
command=['test_model', '%(inputs)s'], name='test_fold%d' % fold,
param_dict={'inputs', []}, has_outputs=True)
test_jobs.append(job_test)
# building the workflow
jobs = [job1] + train_jobs + test_jobs
dependencies = []
links = {}
for fold in range(nfolds):
links[train_jobs[fold]] = {
'inputs': [(job1, 'outputs',
('list_cv_train_fold', fold, nfolds))]}
links[test_jobs[fold]] = {
'inputs': [(job1, 'outputs',
('list_cv_test_fold', fold, nfolds))]}
workflow = Workflow(jobs,
dependencies,
name='train CV', param_links=links)
A leave-one-out pattern example:
# let's say job1 inputs a list and outputs another list, 'outputs'
job1 = Job(
command=['my_program', '%(inputs)s'], name='prepare_inputs',
param_dict={'inputs': ['file1', 'file2', 'file3', 'file4', 'file5']},
has_outputs=True)
# train_jobs are identical train jobs training folds
# they output a single file, 'output'
# test_jobs are identical test jobs testing the single leftover file of
# each fold. They also output a single file, 'output'
nfolds = len(job1.param_dict['inputs'])
train_jobs = []
test_jobs = []
for fold in range(nfolds):
job_train = Job(
command=['train_model', '%(inputs)s'], name='train_fold%d' % fold,
param_dict={'inputs', []}, has_outputs=True)
train_jobs.append(job_train)
job_test = Job(
command=['test_model', '%(input)s'], name='test_fold%d' % fold,
param_dict={'input', 'undefined'}, has_outputs=True)
test_jobs.append(job_test)
# building the workflow
jobs = [job1] + train_jobs + test_jobs
dependencies = []
links = {}
for fold in range(nfolds):
links[train_jobs[fold]] = {
'inputs': [(job1, 'outputs',
('list_all_but_one', fold))]}
links[test_jobs[fold]] = {
'inputs': [(job1, 'outputs',
('list_to_sequence', fold))]}
workflow = Workflow(jobs,
dependencies,
name='train LOO', param_links=links)
A map / reduce example:
# let's say job1 inputs a list and outputs another list, 'outputs'
job1 = Job(
command=['my_program', '%(inputs)s'], name='prepare_inputs',
param_dict={'inputs': ['file1', 'file2', 'file3', 'file4', 'file5']},
has_outputs=True)
# process_jobs are identical train jobs processing one of the input files
# they output a single file, 'output'
nfolds = len(job1.param_dict['inputs'])
process_jobs = []
for fold in range(nfolds):
job_proc = Job(
command=['process_data', '%(input)s'], name='process_%d' % fold,
param_dict={'input', 'undefined'}, has_outputs=True)
process_jobs.append(job_proc)
# a reduce node takes outputs of all processing nodes and, for instance,
# concatenates them
reduce_job = Job(
command=['cat_program', '%(inputs)s'], name='cat_results',
param_dict={'inputs': [], 'outputs': 'file_output'})
# building the workflow
group_1 = Group(name='processing', elements=process_jobs)
jobs = [job1] + process_jobs + [reduce_job]
dependencies = []
links = {}
links[reduce_job] = {'inputs': []}
for fold in range(nfolds):
links[process_jobs[fold]] = {
'inputs': [(job1, 'outputs',
('list_to_sequence', fold))]}
links[reduce_job]['inputs'].append((process_job[fold], 'output',
('sequence_to_list', fold)))
workflow = Workflow(jobs,
root_group=[job1, group_1, reduce_job],
dependencies,
name='map-reduce', param_links=links)
param_link_functions module¶
- param_link_functions.append_to_list(src_param, value, dst_param, dst_value)[source]¶
appends the value value at the end of list dst_value
- param_link_functions.list_all_but_one(item, src_param, value, dst_param, dst_value)[source]¶
remove item-th element from the input list. Useful in a leave-one-out pattern
- param_link_functions.list_cat(item, src_param, value, dst_param, dst_value)[source]¶
concatenates lists: extend value (list) after dst_value
- param_link_functions.list_cv_test_fold(fold, nfolds, src_param, value, dst_param, dst_value)[source]¶
take fold-th division in a list divided into nfold folds. Useful in a nfolds cross-validation pattern
- param_link_functions.list_cv_train_fold(fold, nfolds, src_param, value, dst_param, dst_value)[source]¶
take all but fold-th division in a list divided into nfold folds. Useful in a nfolds cross-validation pattern
- param_link_functions.list_to_sequence(item, src_param, value, dst_param, dst_value)[source]¶
item-th element of list value
- param_link_functions.sequence_max(shift, src_param, value, dst_param, dst_value)[source]¶
get maximum value from a list
- param_link_functions.sequence_min(shift, src_param, value, dst_param, dst_value)[source]¶
get minimum value from a list
Jobs with configuration¶
In Soma-Workflow 3.1 any job in a workflow is allowed to include some runtime configuration data. This is meant especially to enable the use of specific software which needs configuration, paths, or environment variables on the computing resource. This conficuration may of course be passed through environment variables (using the env variable / parameter of Job, but also as a config dictionary which will be passed th the job.
The job configuration is included in the job parameters as in the dynamic output / input arguments passing system. This thus allows 2 ways of passing the config dict to jobs:
as a named job parameter, configuration_dict. In this case this named parameter is reserved for configuration. It is used as another named parameter in the job:
job = Job(command=['my_program', '%(configuration_dict)s'], name='job1', configuration={'conf_var1': 'value1'})
The job will receive the configuration as a JSON string parameter
as a part of a parameters file. In this case the parameters file will be created before the job is run, even if the job does not use the outputs from another job, and the conficuration will be held in a sub-dictionary of this input JSON file, under the key
"configuration_dict", separate from the"params"key. Therefore in this shape,configuration_dictis not a reserved parameter name:job = Job(command=['my_program', name='job1', use_input_params_file=True, configuration={'conf_var1': 'value1'})
As in the dynamic parameters system, when the job is run, the environment variable
SOMAWF_INPUT_PARAMSwill hold the path of the input parameters / configuration file.
Engine execution jobs¶
Soma-Workflow 3.1 introduced EngineExecutionJob. This class is the base class for some special jobs which will actually not run as jobs, but as python functions executed inside the engine process. They should be lightweight in processing, since the engine server should not have a heavy CPU load: it runs on the computing resource submitting machine (a cluster frontal typically) which is not designed to perform actual processing.
Such jobs are meant to perform simple parameters transformations, such as transforming lists into series of single parameter values, or the opposite (map/reduce pattern), or string transformation (get a dirnname for instance) etc.
BarrierJob used to be the only “special job” class in Soma-Workflow 2.10. They are now a subclass of EngineExecutionJob with the particularity of not doing any processing even on engine side.
A few engine execution jobs types have been defined and are available for workflow developers. Other subclasses can be written, but should be installed and available on engine side to work.
BarrierJob: just a dependency hub.MapJob: map part of map/reduce pattern: transforms lists into series of single values parameters.ReduceJob: reduce part of map/reduce pattern: transforms series of single values parameters into list parameters.ListCatJob: conctenates several input lists.LeaveOneOutJob: leve-one-out pattern.CrossValidationFoldJob: cross-validation pattern.
Such jobs are alternatives to Parameters link functions described above.