CAPSUL: chain algorithms in pipelines¶
Capsul is a simple and efficient Python tool that aims to organize a set of processings. It is accessible to everybody, and is reusable in various contexts. The project is hosted on github: https://github.com/populse/capsul.
Documentation: http://populse.github.io/capsul
The following examples are using CAPSUL, and PyQt (or PySide). To get the GUI running in a non-blocking way, the IPython notebook should be started with the option –gui=qt:
ipython notebook --gui=qt
Otherwise calls to the Qt loop will be blocking until windows are closed at each demo step.
Definitions
A Process is a processing that can derived directly from a Python function and that can be used as a building block of a pipeline.
A Pipeline is a series of connected processes.
First check
In order to test if capsul is installed on your machine, you can ask the the Capsul version:
[1]:
# just to ensure compatibility of this notebook with python 2 and 3
from __future__ import print_function
# the following to avoid display when this notebook is converted to sphinx doc
import os
if os.environ.get('ALLOW_GUI', 'TRUE') in ('FALSE', '0'):
use_gui = False
else:
%gui qt4
use_gui = True
from soma.qt_gui import qt_backend
qt_backend.set_qt_backend()
[2]:
import capsul
print(capsul.__version__)
2.6.20
Process and pipeline creation API
A process can be either a Process class instance, or a wrapping of a function
Process and parameters
[3]:
# Capsul import
from capsul.api import Process
# Trait import
from traits.api import Float
class Process1(Process):
f = Float(output=False)
def __init__(self):
super(Process1, self).__init__()
self.add_trait("ff", Float(output=False))
self.add_trait("out", Float(output=True))
def _run_process(self):
self.out = self.f + self.ff
print('Process1 execution, f:', self.f, ', ff:', self.ff)
process = Process1()
print(process.user_traits().keys())
process.ff = 132.6
process.f = 13.3
#execution
process()
print('Process result =', process.out)
['f', 'ff', 'out']
Process1 execution, f: 13.3 , ff: 132.6
Process result = 145.9
[4]:
from traits.api import Str
class Process2(Process):
def __init__(self):
super(Process2, self).__init__()
self.add_trait("a", Float(output=True))
self.add_trait("b", Str(output=False))
def get_commandline(self):
return ['echo', 'Process2 execution, a: %f, b: %s' % (self.a, self.b)]
Use a function as a building block
It is possible to convert a function in Process and thus use it as a building block of a pipeline. In the following example we will use an addition simple Python function:
[5]:
from capsul.process.xml import xml_process
from capsul.api import get_process_instance
@xml_process('''
<process capsul_xml="2.0">
<input name="a" type="int" doc="An integer"/>
<input name="b" type="int" doc="Another integer"/>
<return name="addition" type="int" doc="a + b"/>
</process>
''')
def add(a, b):
return a + b
This is a pure Python function with an XML Process description in the @xml_process decorator. Inside <process> and </process> elements, each input parameters are described as well as the returned value. The parameters are typed and a description is asked in order to generate proper tooltips or documentations. See XML specifications for more information.
We can now create a Process from this Python function:
[6]:
from capsul.api import get_process_instance
process = get_process_instance('__main__.add')
We can set some input parameters and execute the process:
[7]:
process.a = 40
process.b = 2
process()
print(process.a, '+', process.b, '=', process.addition)
40 + 2 = 42
Output files
There is a particular case for output files: a file is a filename (string) and the file itself. When the file itself is an output, the filename may in some cases be an input, when the output filename is specified in advance, or an output when the filename itself is generated by the process and output by it. For the case output file + input filename, we have to specify that the filename is actually an input, and to which parameter it is attached:
[8]:
@xml_process('''
<process capsul_xml="2.0">
<input name="a" type="file" doc="A file"/>
<input name="b" type="file" doc="Another file"/>
<output name="c" type="file" input_filename="c" doc="output concatenated file"/>
</process>
''')
def cat(a, b, c):
with open(c, 'w') as f:
f.write(open(a).read())
f.write(open(b).read())
process = get_process_instance('__main__.cat')
Pipeline
A pipeline uses processes, or sub-pipelines, in order to define a full processing chain, with links between building blocks. A pipeline may be defined either using the Python API, as a Pipeline subclass, or using a XML definition file.
Pipeline API
[9]:
from capsul.api import Pipeline
class Pipeline1(Pipeline):
def pipeline_definition(self):
# Create processes
self.add_process("node1", Process1())
self.add_process("node2", Process2())
pipeline1 = Pipeline1()
Viewing / debugging a pipeline
Pipeline structure
[10]:
if globals().get('use_gui', True):
import sys
# note that the qt backend may be either PyQt4 or PySide.
from soma.qt_gui.qt_backend import QtGui
from capsul.qt_gui.widgets import PipelineDevelopperView
# here we determine whether the Qt GUI is already running or not.
run_qt_loop = False
if QtGui.QApplication.instance() is None:
app = QtGui.QApplication(sys.argv)
run_qt_loop = True
else:
app = QtGui.QApplication.instance()
# in the following we will reuse this run_qt_loop variable for simplicity
# now the real thing for pipeline viewing
view1 = PipelineDevelopperView(pipeline1)
view1.show()
if run_qt_loop:
print('close window to gon on...')
app.exec_()
It should display something like this: 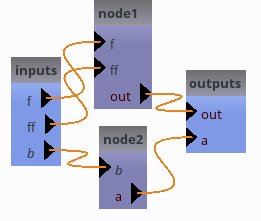
Entering parameters¶
[11]:
if globals().get('use_gui', True):
from soma.qt_gui.controller_widget import ControllerWidget
controller1 = ControllerWidget(pipeline1, live=True)
controller1.show()
controller2 = ControllerWidget(pipeline1, live=True)
controller2.show()
if run_qt_loop:
app.exec_()
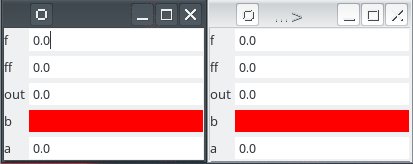
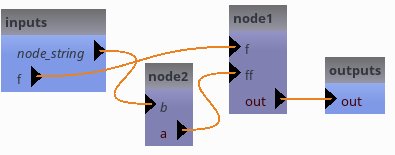
Links and exportations¶
[12]:
class Pipeline2(Pipeline):
def pipeline_definition(self):
# Create processes
self.add_process("node1", Process1())
self.add_process("node2", Process2())
# links
self.add_link('node2.a->node1.ff')
# custom exports
self.export_parameter("node2", "b", "node_string")
[13]:
pipeline2 = Pipeline2()
if globals().get('use_gui', True):
view2 = PipelineDevelopperView(pipeline2)
view2.show()
if run_qt_loop:
app.exec_()
[14]:
pipeline2.f = 13.2
pipeline2.node_string = "blop"
pipeline2()
Process2 execution, a: 0.000000, b: blop
Process1 execution, f: 13.2 , ff: 0.0
Defining a Pipeline from XML a file
A Pipeline can be described from an xml file. For the documentation of the description glossary, please refer to the capsul documentation. In the following example we will use the ‘xml_pipeline.xml’ test description. See XML specifications for more information.
[15]:
import os
import capsul.process.test as test
xmldesc = os.path.join(os.path.dirname(test.__file__), "xml_pipeline.xml")
with open(xmldesc, "r") as openfile:
print("".join(openfile.readlines()))
<pipeline>
<doc>
Auto Generated Pipeline Test
</doc>
<process name="p1"
module="capsul.process.test.test_load_from_description.a_function_to_wrap">
<set name="list_of_str" value="['test']"/>
</process>
<process name="p2"
module="capsul.process.test.test_load_from_description.a_function_to_wrap"/>
<link source="p1.string" dest="p2.fname"/>
<link source="pdirectory" dest="p2.directory"/>
<link source="value" dest="p2.value"/>
<link source="enum" dest="p2.enum"/>
<link source="list_of_str" dest="p2.list_of_str"/>
<link source="value" dest="p1.value"/>
<link source="enum" dest="p1.enum"/>
<link source="fname" dest="p1.fname"/>
<link source="list_of_str" dest="p1.list_of_str"/>
<link source="pdirectory" dest="p1.directory"/>
<link dest="out1" source="p2.string"/>
<gui>
<position name="inputs" x="0" y="0"/>
<position name="p1" x="200" y="200"/>
<position name="p2" x="400" y="-200"/>
<position name="outputs" x="600" y="0"/>
<zoom level="1"/>
</gui>
</pipeline>
Two building blocks are connected in this example. We will soon have a graphical representation of the pipeline, which in turn will clarify the xml sections. But first we must create a Pipeline from this xml description:
[16]:
from capsul.api import get_process_instance
xmlpipe = get_process_instance("capsul.process.test.xml_pipeline")
xmlpipe.help()
Auto Generated Pipeline Test
.. note::
* Type 'ProcessMeta.help()' for a full description of this process parameters.
* Type '<ProcessMeta>.get_input_spec()' for a full description of this process input trait types.
* Type '<ProcessMeta>.get_output_spec()' for a full description of this process output trait types.
Inputs
~~~~~~
[Mandatory]
nodes_activation: a legal value (['ControllerTrait'] - mandatory)
No description.
pdirectory: a string or os.PathLike object (['Directory'] - mandatory)
test
value: a float (['Float'] - mandatory)
test
enum: a string (['String'] - mandatory)
test
list_of_str: a legal value (['List_String'] - mandatory)
test
fname: a string or os.PathLike object (['File'] - mandatory)
test
Outputs
~~~~~~~
out1: a string (['String'] - mandatory)
test
One major advantage of the capsul pipeline system is to be able to represent graphically the processing sequence:
[17]:
if globals().get('use_gui', True):
import sys
from soma.qt_gui.qt_backend import QtGui
from capsul.qt_gui.widgets import PipelineDevelopperView
from soma.qt_gui.controller_widget import ControllerWidget
view = PipelineDevelopperView(xmlpipe)
controller = ControllerWidget(xmlpipe, live=True)
view.show()
controller.show()
if run_qt_loop:
app.exec_()
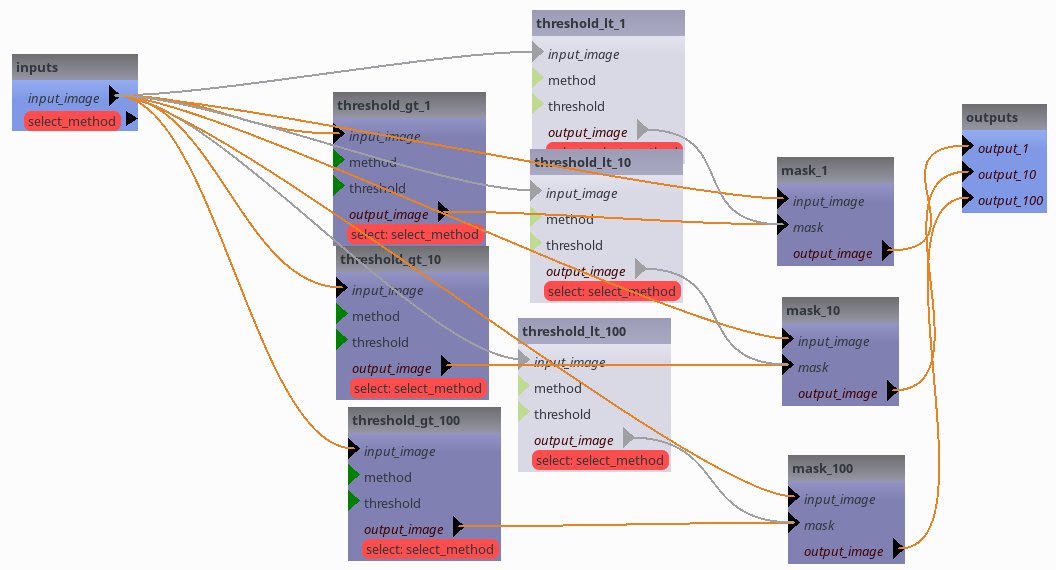
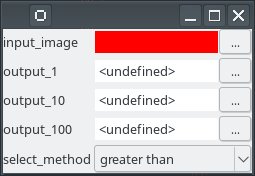
Switches¶
In Capsul it is possible to define a building block which aims to select a sequence of processings. It is done with a Switch building block as follows:
Using the Python API¶
[18]:
class Pipeline3(Pipeline):
def pipeline_definition(self):
# Create processes
self.add_process("node1", Process1())
self.add_process("node2", Process2())
self.add_switch("switch", ["case1", "case2"], ["output"])
#links
self.add_link("node1.out->switch.case1_switch_output")
self.add_link("node2.a->switch.case2_switch_output")
[19]:
pipeline3 = Pipeline3()
if globals().get('use_gui', True):
view3 = PipelineDevelopperView(pipeline3, allow_open_controller=True, show_sub_pipelines=True)
view3.show()
if run_qt_loop:
app.exec_()
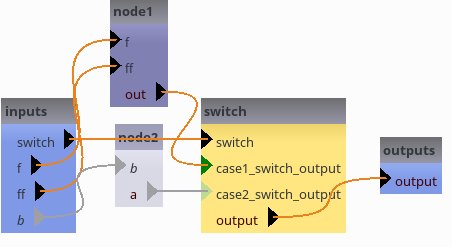
[20]:
pipeline3.switch = "case2"
if globals().get('use_gui', True):
view3.show()
if run_qt_loop:
app.exec_()
[21]:
pipeline3(b='yup')
Process2 execution, a: 0.000000, b: yup
Using XML definition
[22]:
import os
import capsul.process.test as test
xmldesc = os.path.join(os.path.dirname(test.__file__), "test_pipeline.xml")
with open(xmldesc, "r") as openfile:
print("".join(openfile.readlines()))
<pipeline capsul_xml="2.0">
<process name="threshold_gt_1"
module="capsul.process.test.test_load_from_description.threshold">
<set name="threshold" value="1"/>
<set name="method" value="'gt'"/>
</process>
<process name="threshold_gt_10"
module="capsul.process.test.test_load_from_description.threshold">
<set name="threshold" value="10"/>
<set name="method" value="'gt'"/>
</process>
<process name="threshold_gt_100"
module="capsul.process.test.test_load_from_description.threshold">
<set name="threshold" value="100"/>
<set name="method" value="'gt'"/>
</process>
<process name="threshold_lt_1"
module="capsul.process.test.test_load_from_description.threshold">
<set name="threshold" value="1"/>
<set name="method" value="'lt'"/>
</process>
<process name="threshold_lt_10"
module="capsul.process.test.test_load_from_description.threshold">
<set name="threshold" value="10"/>
<set name="method" value="'lt'"/>
</process>
<process name="threshold_lt_100"
module="capsul.process.test.test_load_from_description.threshold">
<set name="threshold" value="100"/>
<set name="method" value="'lt'"/>
</process>
<process name="mask_1"
module="capsul.process.test.test_load_from_description.mask">
</process>
<process name="mask_10"
module="capsul.process.test.test_load_from_description.mask">
</process>
<process name="mask_100"
module="capsul.process.test.test_load_from_description.mask">
</process>
<link source="input_image" dest="threshold_gt_1.input_image"/>
<link source="input_image" dest="threshold_gt_10.input_image"/>
<link source="input_image" dest="threshold_gt_100.input_image"/>
<link source="input_image" dest="threshold_lt_1.input_image"/>
<link source="input_image" dest="threshold_lt_10.input_image"/>
<link source="input_image" dest="threshold_lt_100.input_image"/>
<link source="input_image" dest="mask_1.input_image"/>
<link source="input_image" dest="mask_10.input_image"/>
<link source="input_image" dest="mask_100.input_image"/>
<link source="threshold_gt_1.output_image" dest="mask_1.mask"/>
<link source="threshold_gt_10.output_image" dest="mask_10.mask"/>
<link source="threshold_gt_100.output_image" dest="mask_100.mask"/>
<link source="threshold_lt_1.output_image" dest="mask_1.mask"/>
<link source="threshold_lt_10.output_image" dest="mask_10.mask"/>
<link source="threshold_lt_100.output_image" dest="mask_100.mask"/>
<link source="mask_1.output_image" dest="output_1"/>
<link source="mask_10.output_image" dest="output_10"/>
<link source="mask_100.output_image" dest="output_100"/>
<processes_selection name="select_method">
<processes_group name="greater than">
<process name="threshold_gt_1"/>
<process name="threshold_gt_10"/>
<process name="threshold_gt_100"/>
</processes_group>
<processes_group name="lower than">
<process name="threshold_lt_1"/>
<process name="threshold_lt_10"/>
<process name="threshold_lt_100"/>
</processes_group>
</processes_selection>
<gui>
<position name="threshold_gt_100" x="386.0" y="403.0"/>
<position name="inputs" x="50.0" y="50.0"/>
<position name="mask_1" x="815.0" y="153.0"/>
<position name="threshold_gt_10" x="374.0" y="242.0"/>
<position name="threshold_lt_100" x="556.0" y="314.0"/>
<position name="threshold_gt_1" x="371.0" y="88.0"/>
<position name="mask_10" x="820.0" y="293.0"/>
<position name="mask_100" x="826.0" y="451.0"/>
<position name="threshold_lt_1" x="570.0" y="6.0"/>
<position name="threshold_lt_10" x="568.0" y="145.0"/>
<position name="outputs" x="1000" y="100" />
<!--
<position name="threshold_gt_100" x="182.35615" y="658.8043">
<position name="mask_1" x="348.3267625" y="205.125">
<position name="threshold_gt_10" x="183.6139625" y="329.3854">
<position name="inputs" x="0.0" y="488.9169">
<position name="outputs" x="512.08755" y="488.9169">
<position name="mask_100" x="348.3267625" y="744.8167">
<position name="threshold_lt_1" x="183.6139625" y="146.998">
<position name="threshold_gt_1" x="183.6139625" y="0.0">
<position name="threshold_lt_100" x="183.6139625" y="805.8291">
<position name="mask_10" x="348.3267625" y="488.9169">
<position name="threshold_lt_10" x="183.6139625" y="476.4169">
-->
</gui>
</pipeline>
Again we can create a Pipeline from his xml description:
[23]:
from capsul.api import get_process_instance
xmlpipe = get_process_instance("capsul.process.test.test_pipeline")
xmlpipe.help()
.. note::
* Type 'test_pipeline.help()' for a full description of this process parameters.
* Type '<test_pipeline>.get_input_spec()' for a full description of this process input trait types.
* Type '<test_pipeline>.get_output_spec()' for a full description of this process output trait types.
Inputs
~~~~~~
[Mandatory]
nodes_activation: a legal value (['ControllerTrait'] - mandatory)
No description.
input_image: a string or os.PathLike object (['File'] - mandatory)
Path of a NIFTI-1 image file.
select_method: a legal value (['Enum'] - mandatory)
No description.
Outputs
~~~~~~~
output_1: a string or os.PathLike object (['File (filename: output)']
- mandatory)
Output file name.
output_10: a string or os.PathLike object (['File (filename: output)']
- mandatory)
Output file name.
output_100: a string or os.PathLike object (['File (filename:
output)'] - mandatory)
Output file name.
And generate its graphical representation:
[24]:
if globals().get('use_gui', True):
from soma.qt_gui.qt_backend import QtGui
from capsul.qt_gui.widgets import PipelineDevelopperView
from soma.qt_gui.controller_widget import ControllerWidget
view = PipelineDevelopperView(xmlpipe)
controller = ControllerWidget(xmlpipe, live=True)
view.show()
controller.show()
if run_qt_loop:
app.exec_()
Iteration over a process or pipeline¶
A process can be used several times in parallel: some of its parameters will be changed for lists
[25]:
@xml_process('''<process capsul_xml="2.0">
<input name="inputs" type="list_float" doc="numbers"/>
<return name="addition" type="float" doc="sum all inputs"/>
</process>
''')
def sum_node(inputs):
return sum(inputs)
@xml_process('''<process capsul_xml="2.0">
<input name="a" type="float" doc="number"/>
<return name="b" type="float" doc="a + 12"/>
</process>
''')
def add_12(a):
return a + 12
class Pipeline4(Pipeline):
def pipeline_definition(self):
self.add_iterative_process("add_12", '__main__.add_12', iterative_plugs=['a', 'b'])
self.add_process("sum_node", '__main__.sum_node')
self.add_link('add_12.b->sum_node.inputs')
[26]:
pipeline4 = Pipeline4()
if globals().get('use_gui', True):
view4 = PipelineDevelopperView(pipeline4, allow_open_controller=True, show_sub_pipelines=True)
view4.show()
if run_qt_loop:
app.exec_()
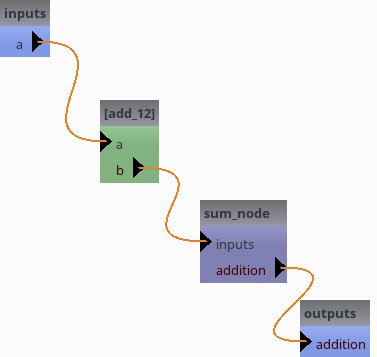 The green node here is an iterative node, it can be opened (double-clicked) to see what is inside it.
The green node here is an iterative node, it can be opened (double-clicked) to see what is inside it.
Set input parameters and run.
We set 3 inputs, 4.2, 6.8 and 7.
Each should be added 12, then all outputs will be summed up.
This should make (4.2 + 12) + (6.8 + 12) + (7. + 12) = 54.
[27]:
pipeline4.a = [4.2, 6.8, 7.]
pipeline4()
print(pipeline4.addition)
assert(pipeline4.addition == 54)
54.0
Optional outputs and temporary files
Let’s consider the following pipeline, with an optional output from the intermediate output:
[28]:
@xml_process('''<process capsul_xml="2.0">
<input name="input" type="file" doc="input file"/>
<output name="output" type="file" input_filename="output" doc="output file"/>
</process>
''')
def node_first(input, output):
lines = open(input).readlines()
with open(output, 'w') as f:
f.write('\n'.join(['* %s *' % l[:-1] for l in lines]))
@xml_process('''<process capsul_xml="2.0">
<input name="a" type="file" doc="input file"/>
<output name="b" type="file" input_filename="b" doc="output file"/>
</process>
''')
def node_second(a, b):
lines = open(a).readlines()
with open(b, 'w') as f:
f.write(''.join([l.replace('*', '^') for l in lines]))
class Pipeline5(Pipeline):
def pipeline_definition(self):
self.add_process("node1", '__main__.node_first')
self.add_process("node2", '__main__.node_second')
self.add_link('node1.output->node2.a')
self.export_parameter('node1', 'output', 'intermediate', is_optional=True)
[29]:
pipeline5 = Pipeline5()
if globals().get('use_gui', True):
view5 = PipelineDevelopperView(pipeline5, allow_open_controller=True, show_sub_pipelines=True)
view5.show()
if run_qt_loop:
app.exec_()
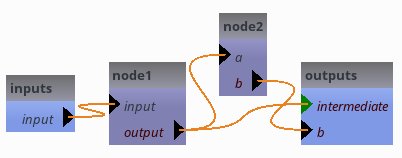
But there is really a problem here now: if we do not specify pipeline5.intermediate, even when it is optional, the pipeline will not work because node1 needs to write its output into a file. As its output is exported, it will not get a temporary value. Thus in the current state, pipeline5.intermediate is actually mandatory.
[30]:
infile = '/tmp/dummy.txt'
outfile = '/tmp/dummy_modified.txt'
intermediate = '/tmp/dummy_intermediate.txt'
open(infile, 'w').write('I ate 5 cakes this morning.\nLet\'s eat 3 or 4 more.\n')
pipeline5.input = infile
pipeline5.b = outfile
pipeline5.intermediate = intermediate
pipeline5()
print(open(outfile).read())
^ I ate 5 cakes this morning. ^
^ Let's eat 3 or 4 more. ^
[31]:
# cleanup
os.unlink(outfile)
os.unlink(intermediate)
To solve this issue, we need an element which conditionally bridges or breaks the link between node1.output and intermediate. This is the job of optional output switches:
[32]:
class Pipeline6(Pipeline):
def pipeline_definition(self):
self.add_process("node1", '__main__.node_first')
self.add_process("node2", '__main__.node_second')
self.add_optional_output_switch('b', 'input')
self.add_link('node1.output->node2.a')
self.add_link('node1.output->b.input_switch_b')
self.export_parameter('b', 'b', 'intermediate', is_optional=True)
[33]:
pipeline6 = Pipeline6()
if globals().get('use_gui', True):
view6 = PipelineDevelopperView(pipeline6, allow_open_controller=True, show_sub_pipelines=True)
view6.show()
if run_qt_loop:
app.exec_()
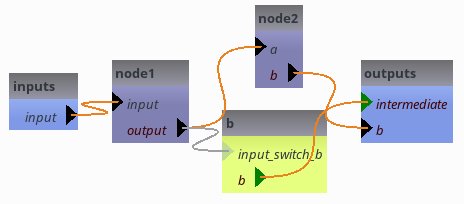
as long as pipeline6.intermediate is empty, the switch is off. node1.output gets a temporary value.
[34]:
pipeline6.input = infile
pipeline6.b = outfile
pipeline6()
print(open(outfile).read())
^ I ate 5 cakes this morning. ^
^ Let's eat 3 or 4 more. ^
[35]:
# cleanup
os.unlink(outfile)
[36]:
pipeline6.intermediate = intermediate
[37]:
# the switch has been switched on automatically
# node1.output gets the value assigned to pipeline6.intermediate
if globals().get('use_gui', True):
view6.show()
if run_qt_loop:
app.exec_()
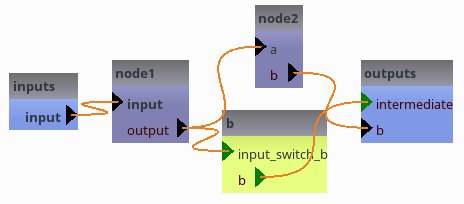
[38]:
pipeline6()
print(open(intermediate).read())
* I ate 5 cakes this morning. *
* Let's eat 3 or 4 more. *
[39]:
# cleanup
os.unlink(outfile)
os.unlink(intermediate)
os.unlink(infile)
StudyConfig
StudyConfig is a placeholder for study-wide parameters, settings, paths and so on. It is a modular configuration tool, which has modules to configure some external software.
A helper to configure state of the art medical software
Capsul propose a module to configure external software:
FSL
SPM
FreeSurfer
BrainVisa
With this module it is also possible to configure the execution of the pipeline:
Use smart caching
Generate some logging
Soma-Worflow to handle population imaging
For instance:
[40]:
from capsul.api import StudyConfig
# optional config modules, need not to be explicitly loaded
# from capsul.study_config.config_modules.freesurfer_config import FreeSurferConfig
# from capsul.study_config.config_modules.brainvisa_config import BrainVISAConfig
default_config = {"use_soma_workflow": True}
study_config = StudyConfig(initial_config=default_config,
modules=StudyConfig.default_modules + \
['BrainVISAConfig', 'FSLConfig', 'FomConfig'])
# inspect config options
for k in study_config.user_traits().keys(): print(k, ': ', getattr(study_config, k))
create_output_directories : True
generate_logging : False
input_directory : <undefined>
output_directory : <undefined>
process_output_directory : False
study_name : <undefined>
user_level : 0
afni_path : <undefined>
use_afni : <undefined>
ants_path : <undefined>
use_ants : <undefined>
fsl_config : <undefined>
fsl_prefix : <undefined>
use_fsl : <undefined>
matlab_exec : <undefined>
use_matlab : False
mrtrix_path : <undefined>
use_mrtrix : <undefined>
use_smart_caching : False
use_soma_workflow : False
somaworkflow_computing_resource : <undefined>
somaworkflow_config_file : <undefined>
somaworkflow_keep_failed_workflows : True
somaworkflow_keep_succeeded_workflows : False
somaworkflow_computing_resources_config : <soma.controller.controller.OpenKeyController object at 0x7f9d30bb5350>
spm_directory : <undefined>
spm_standalone : <undefined>
spm_version : <undefined>
spm_exec : <undefined>
spm_mcr_directory : <undefined>
use_spm : <undefined>
shared_directory : /opt/hostedtoolcache/Python/3.10.20/x64/lib/python3.10/site-packages/share/brainvisa-share-6.0
input_fom :
output_fom :
shared_fom :
volumes_format : <undefined>
meshes_format : <undefined>
auto_fom : True
fom_path : []
use_fom : True
attributes_schema_paths : ['capsul.attributes.completion_engine_factory']
attributes_schemas : {}
process_completion : builtin
path_completion : <undefined>
Let show how to configure FSL:
[41]:
from capsul.api import StudyConfig
study_config = StudyConfig(
modules=["FSLConfig"],
fsl_config="/etc/fsl/5.0/fsl.sh",
use_smart_caching=True,
output_directory="/tmp/capsul_demo")
print(study_config.run.__doc__)
Method to execute a process or a pipeline in a study configuration
environment.
Depending on the studies_config settings, it may be a sequential run,
or a parallel run, which can involve remote execution (through soma-
workflow).
Only pipeline nodes can be filtered on the 'execute_qc_nodes'
attribute.
A valid output directory is expected to execute the process or the
pepeline without soma-workflow.
Parameters
----------
process_or_pipeline: Process or Pipeline instance (mandatory)
the process or pipeline we want to execute
output_directory: Directory name (optional)
the output directory to use for process execution. This replaces
self.output_directory but left it unchanged.
execute_qc_nodes: bool (optional, default False)
if True execute process nodes that are tagged as qualtity control
process nodes.
verbose: int
if different from zero, print console messages.
configuration_dict: dict (optional)
configuration dictionary
Execution of the pipeline
In this section a simple execution is performed on your machine using one CPU (if more than one CPU are used it means that the called external software is parallelized). We just have to call the StudyConfig run method:
[42]:
study_config.reset_process_counter()
study_config.run(pipeline2, verbose=1)
________________________________________________________________________________
[Process] Calling __main__.Process2...
__main__.Process2(b=blop)
Process2 execution, a: 0.000000, b: blop
________________________________________________________________________________
[Process] Calling __main__.Process1...
__main__.Process1(f=13.2, ff=0.0)
Process1 execution, f: 13.2 , ff: 0.0
Distributed execution using Soma-Workflow
Capsul can execute a pipeline through Soma-Workflow in order to address large parallelized pipelines, or huge datasets in the case of population imaging studies.
Limitation:
Currently, when used in Soma-Workflow, process outputs can only be files. Output numbers, strings, etc. will be lost.
[43]:
class Process1(Process):
f = Float(output=False)
def __init__(self):
super(Process1, self).__init__()
self.add_trait("ff", Float(output=False))
self.add_trait("out", Float(output=True))
def get_commandline(self):
return ['echo', 'Process1 execution, f: %f, ff: %f' % (self.f, self.ff)]
class Process2(Process):
def __init__(self):
super(Process2, self).__init__()
self.add_trait("a", Float(output=True))
self.add_trait("b", Str(output=False))
def get_commandline(self):
return ['echo', 'Process2 execution, a: %f, b: %s' % (self.a, self.b)]
class Pipeline2(Pipeline):
def pipeline_definition(self):
# Create processes
self.add_process("node1", Process1())
self.add_process("node2", Process2())
# links
self.add_link('node2.a->node1.ff')
# custom exports
self.export_parameter("node2", "b", "node_string")
[44]:
from capsul.pipeline.pipeline_workflow import workflow_from_pipeline
pipeline2 = get_process_instance(Pipeline2)
workflow = workflow_from_pipeline(pipeline2)
print('jobs:', workflow.jobs)
print('dependencies:', workflow.dependencies)
jobs: [<soma_workflow.client_types.Job object at 0x7f9d30f62e00>, <soma_workflow.client_types.Job object at 0x7f9d30f62830>]
dependencies: {(<soma_workflow.client_types.Job object at 0x7f9d30f62830>, <soma_workflow.client_types.Job object at 0x7f9d30f62e00>)}
The workwlow can be saved and reloaded in soma_workflow_gui, or used in a soma-workflow controller:
[45]:
from soma_workflow import client as swclient
# save workflow to disk in json format
swclient.Helper.serialize('/tmp/pipeline2.workflow', workflow)
# run locally via a workflow controller
wc = swclient.WorkflowController()
wf_id = wc.submit_workflow(workflow)
swclient.Helper.wait_workflow(wf_id, wc)
print('execution status:', wc.workflow_status(wf_id))
wc.delete_workflow(wf_id)
soma-workflow starting in light mode
Workflow controller initialised
execution status: workflow_done
[45]:
True
ok if we don’t use it anymore, we can remove this workflow file.
[46]:
import os
os.unlink('/tmp/pipeline2.workflow')
More transparently, Soma-Workflow execution can be used from StudyConfig: For this, StudyConfig should have “SomaWorkflowConfig” amongst its modules, and it should be enabled (which should be the default when the module is loaded in the config).
[47]:
study_config = StudyConfig(modules=['SomaWorkflowConfig'])
study_config.use_soma_workflow = True
study_config.run(pipeline2)
# if execution fails, an exception should be raised.
soma-workflow starting in light mode
Workflow controller initialised
If we wanted more control over the executed workflow, we could have added things:
[48]:
study_config.somaworkflow_keep_succeeded_workflows = True
wc = study_config.modules['SomaWorkflowConfig'].get_workflow_controller()
if wc is not None:
init_wf_list = wc.workflows().keys()
else:
init_wf_list = []
try:
study_config.run(pipeline2)
except Exception as e:
print('Workflow failed:', e)
# get workflow after running
wc = study_config.modules['SomaWorkflowConfig'].get_workflow_controller()
wf_list = wc.workflows().keys()
wf_id = [wf for wf in wf_list if wf not in init_wf_list][0]
print('workflow id:', wf_id)
wc.delete_workflow(wf_id)
del WorkflowController
workflow id: 3
[48]:
True
Use third-party software in Capsul
Some third-party software need to be configured before they are called. StudyConfig is used to hold this configuration. There are a set of modules that can be modified to enable/disable configuration of third-party software.
[49]:
from capsul.api import StudyConfig
print(StudyConfig.default_modules)
['AFNIConfig', 'ANTSConfig', 'FSLConfig', 'MatlabConfig', 'MRTRIXConfig', 'SmartCachingConfig', 'SomaWorkflowConfig', 'SPMConfig']
In order to change modules that are used, one must give a full module list to StudyConfig():
[50]:
study_config = StudyConfig(modules=StudyConfig.default_modules + ['BrainVISAConfig', 'NipypeConfig'])
Use FSL in Capsul
FSL is called via specific subprocess-like functions taking into account a configuration done in StudyConfig. If a StudyConfig is not configured to use FSL, it may be automatically configured. Automatic configuration had been tested in the two following cases :
FSL was installed from the FMRIB site and, at least, FSLDIR environment variable is set (fsl.sh can be sourced or not)
FSL was installed from Neurodebian packages
Automatic configuration is done lazily. To start it, one must either use StudyConfig(use_fsl=True) or use one of the calling functions of capsul.subprocess.fsl.
For calling FSL command with capsul.subprocess.fsl module, the first argument of command line must be the FSL executable without any path nor prefix. Prefix are used in Neurodebian install. For instance on Ubuntu 16.04 Neurodebian FSL commands are prefixed with fsl5.0-. The appropriate path and eventually prefix are added from the configuration of the StudyConfig instance.
[51]:
import sys
import os
import os.path as osp
import tempfile
from traits.api import File, Undefined
from capsul.api import StudyConfig, Process
from capsul.in_context import fsl
class Bet(Process):
'''
A process that calls bet command without any parameter except input and output files.
'''
input_image = File(optional=False, output=False)
output_image = File(optional=False, output=True)
def _run_process(self):
fsl.fsl_check_call(['bet', self.input_image, self.output_image])
try:
study_config = StudyConfig(use_fsl=True)
except EnvironmentError as e:
# If FSL cannot be configured automatically, tells why
print('FSL cannot be configured automatically:', str(e))
study_config = None
if study_config and study_config.use_fsl is True:
with study_config.engine:
# Try to find an image in FSL installation directory
test_image = '/usr/share/data/fsl-mni152-templates/MNI152_T1_1mm_brain.nii.gz'
if not osp.exists(test_image):
fsl_dir = os.environ.get('FSLDIR')
if not fsl_dir and study_config.fsl_config is not Undefined:
fsl_dir = osp.dirname(osp.dirname(osp.dirname(study_config.fsl_config)))
if fsl_dir:
test_image = glob(osp.join(fsl_dir, 'fslpython/envs/fslpython/lib/python*/site-packages/nibabel/tests/data/anatomical.nii'))
if test_image:
test_image = test_image[0]
else:
print('FSL test data cannot be found')
test_image = None
if test_image:
bet = study_config.get_process_instance(Bet)
with tempfile.NamedTemporaryFile(suffix='.nii.gz') as tmp:
bet.run(input_image=test_image, output_image=tmp.name)
print('Output file size:', os.stat(bet.output_image).st_size)
FSL cannot be configured automatically: FSL command "bet" cannot be found in PATH
Use Nipype in Capsul
It is possible to use all the nipype interfaces (FSL, SPM, FreeSurfer, …) as building blocks in Capsul. This step requires nipype to be properly installed as well as the software we want to use. For instance if we want to perform a brain extraction with FSL we can simply write:
[52]:
from capsul.api import StudyConfig, get_process_instance
from soma.path import find_in_path
study_config = StudyConfig(modules=StudyConfig.default_modules + ['NipypeConfig'])
# It is necessary to have FLS commands (such as "bet") in
# the PATH in order to use FSL via Nipype
if study_config.use_nipype and find_in_path('bet'):
betpipe = get_process_instance("nipype.interfaces.fsl.BET")
betpipe.get_help()
betpipe.in_file="/tmp/MNI152_T1_2mm.nii.gz"
betpipe.output_directory = '/tmp'
else:
betpipe = None
print('NiPype is not present.')
NiPype is not present.
As shown it is possible to set the BET algorithm input parameters. Note that in capsul the standard nipype outputs are prefixed with underscores. We can execute this Process but unfortunately, as mentioned by the nipype warnings, FSL needs to be configured in the study confit, otherwise the pipeline will not run. As we have done it above, we can run it:
[53]:
if betpipe:
study_config.reset_process_counter()
study_config.run(betpipe, verbose=1)
Parameters completion using FOM (File Organization Model)
FOMs allow to complete file names in large pipelines with many parameters from a small set of attributes. To illustrate this feature, we will first create a pipeline with several such parameters, from a XML description.
[54]:
from capsul.pipeline.xml import create_xml_pipeline
xmlstr = '''<pipeline capsul_xml="2.0">
<process name="proc1"
module="capsul.pipeline.test.test_pipeline.DummyProcess">
</process>
<process name="proc2"
module="capsul.pipeline.test.test_pipeline.DummyProcess">
</process>
<process name="proc3"
module="capsul.pipeline.test.test_pipeline.DummyProcess">
</process>
<process name="proc4"
module="capsul.pipeline.test.test_pipeline.DummyProcess">
</process>
<switch name="proc_select" switch_value="proc1">
<input name="proc1"/>
<input name="proc2"/>
<output name="image"/>
</switch>
<switch name="proc_select2" switch_value="proc3">
<input name="proc3"/>
<input name="proc4"/>
<output name="image"/>
</switch>
<link source="input_image1" dest="proc1.input_image"/>
<link source="input_image2" dest="proc2.input_image"/>
<link source="proc_select" dest="proc_select.switch"/>
<link source="proc_select2" dest="proc_select2.switch"/>
<link source="input_image4" dest="proc4.input_image"/>
<link source="input_image3" dest="proc3.input_image"/>
<link dest="image_out1" source="proc_select.image" weak_link="true"/>
<link dest="image_out3" source="proc3.output_image" weak_link="true"/>
<link dest="image_out5" source="proc_select2.image" weak_link="true"/>
<link source="input_image1" dest="proc1.input_image"></link>
<link source="input_image2" dest="proc2.input_image"></link>
<link source="proc_select" dest="proc_select.switch"></link>
<link source="proc_select2" dest="proc_select2.switch"></link>
<link source="input_image4" dest="proc4.input_image"></link>
<link source="input_image3" dest="proc3.input_image"></link>
<link source="proc1.output_image" dest="proc_select.proc1_switch_image"></link>
<link source="proc2.output_image" dest="proc_select.proc2_switch_image"></link>
<link source="proc3.output_image" dest="proc_select2.proc3_switch_image"></link>
<link source="proc4.output_image" dest="proc_select2.proc4_switch_image"></link>
<gui>
<position name="inputs" x="-151.0" y="227.4447"></position>
<position name="proc_select" x="381.6498" y="160.1012"></position>
<position name="outputs" x="668.1498" y="319.9886"></position>
<position name="proc_select2" x="381.6498" y="507.1947"></position>
<position name="proc4" x="144.2624" y="589.7949"></position>
<position name="proc1" x="123.2624" y="-4.0"></position>
<position name="proc3" x="146.2624" y="391.9886"></position>
<position name="proc2" x="132.2624" y="171.8197"></position>
</gui>
</pipeline>'''
DemoPipeline = create_xml_pipeline('__main__', 'DemoPipeline', xmlstr)
pipeline = DemoPipeline()
[55]:
if globals().get('use_gui', True):
from capsul.qt_gui.widgets import PipelineDevelopperView
pv = PipelineDevelopperView(pipeline, allow_open_controller=True, show_sub_pipelines=True)
pv.show()
if run_qt_loop:
app.exec_()
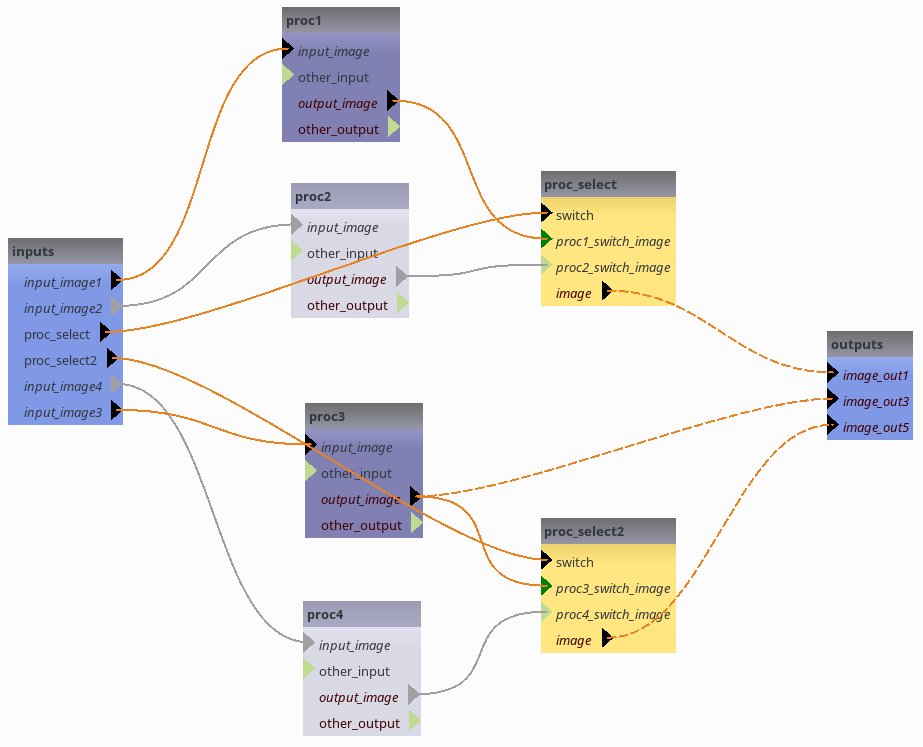
FOM definition¶
[56]:
fom_content = '''{
"fom_name": "demo_fom",
"formats": {
"NIFTI": "nii",
"NIFTI gz": "nii.gz"
},
"format_lists": {
"images": ["NIFTI gz", "NIFTI"]
},
"shared_patterns": {
"subject_dir": "<center>_<subject>"
},
"processes": {
"DemoPipeline": {
"input_image1":
[["input:<center>_<subject>/<subject>", "images"]],
"input_image2":
[["input:{subject_dir}/alt2_<subject>", "images"]],
"input_image3":
[["input:{subject_dir}/alt2_<subject>", "images"]],
"input_image4":
[["input:{subject_dir}/alt4_<subject>", "images"]],
"image_out1":
[["output:{subject_dir}/out_image_<subject>_1", "images"]],
"image_out3":
[["output:{subject_dir}/out_image_<subject>_3", "images"]]
},
"DemoPipeline.proc4": {
"output_image": [["output:{subject_dir}/out_image_<subject>_4", "images"]]
}
}
}
'''
try: os.path.makedirs('/tmp/capsul_demo')
except: pass
open('/tmp/capsul_demo/demo_fom.json', 'w').write(fom_content)
[56]:
1035
File names completion using FOM
FOM completion is used through the attributes completion system ProcessCompletionEngine.
[57]:
import sys
import os
from capsul.api import StudyConfig
from capsul.attributes.completion_engine import ProcessCompletionEngine
if globals().get('use_gui', True):
from soma.qt_gui.controller_widget import ScrollControllerWidget
from capsul.qt_gui.widgets.attributed_process_widget import AttributedProcessWidget
# the following 4 lines are a hack to add /tmp/capsul_demo to the FOM search path
# before it is used by StudyConfig
from soma.application import Application
soma_app = Application('capsul', plugin_modules=['soma.fom'])
soma_app.initialize()
soma_app.fom_manager.paths.append('/tmp/capsul_demo')
config = {
"name" : "morphologist_fom",
"input_directory" : "/data/capsul_demo",
"output_directory" : "/data/capsul_demo",
"input_fom" : "demo_fom",
"output_fom" : "demo_fom",
"use_soma_workflow" : True,
"use_fom" : True,
"volumes_format" : "nii.gz",
"meshes_format" : "gii",
}
study_config = StudyConfig(init_config=config,
modules=StudyConfig.default_modules + ['FomConfig', 'BrainVISAConfig'])
soma_app.fom_manager._cache = None # while debugging
mp = study_config.get_process_instance(DemoPipeline)
ce = ProcessCompletionEngine.get_completion_engine(mp)
print('completion engine type:', type(ce).__name__)
attributes = ce.get_attribute_values()
ce.install_auto_completion()
attributes.center = 'subjects'
attributes.subject = 'irm2'
if globals().get('use_gui', True):
# pipeline controller GUI
p_view = ScrollControllerWidget(mp, live=True)
p_view.show()
# attributed pipeline controller GUI
ap_view = AttributedProcessWidget(mp)
ap_view.show()
pv = PipelineDevelopperView(mp, allow_open_controller=True, show_sub_pipelines=True)
pv.show()
if run_qt_loop:
app.exec_()
completion engine type: FomProcessCompletionEngine
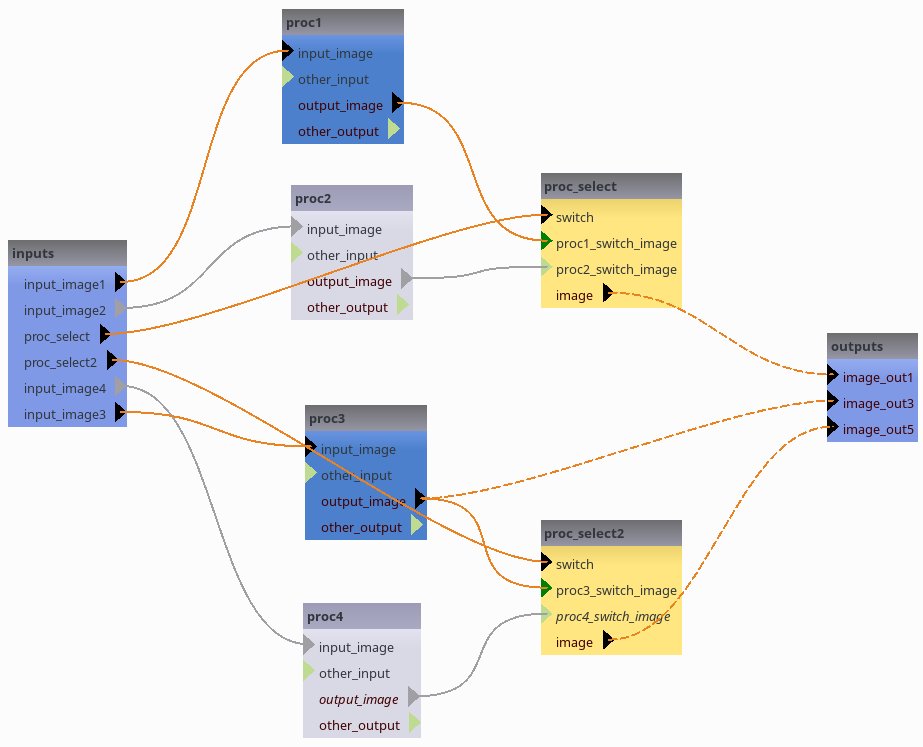
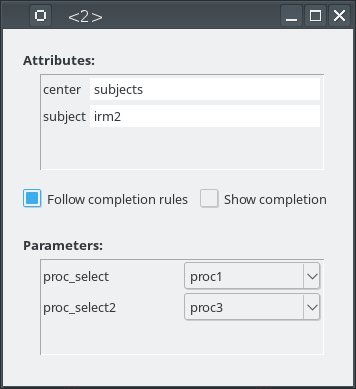
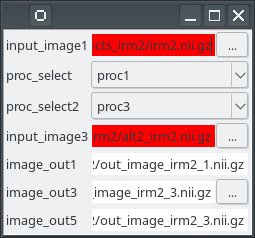
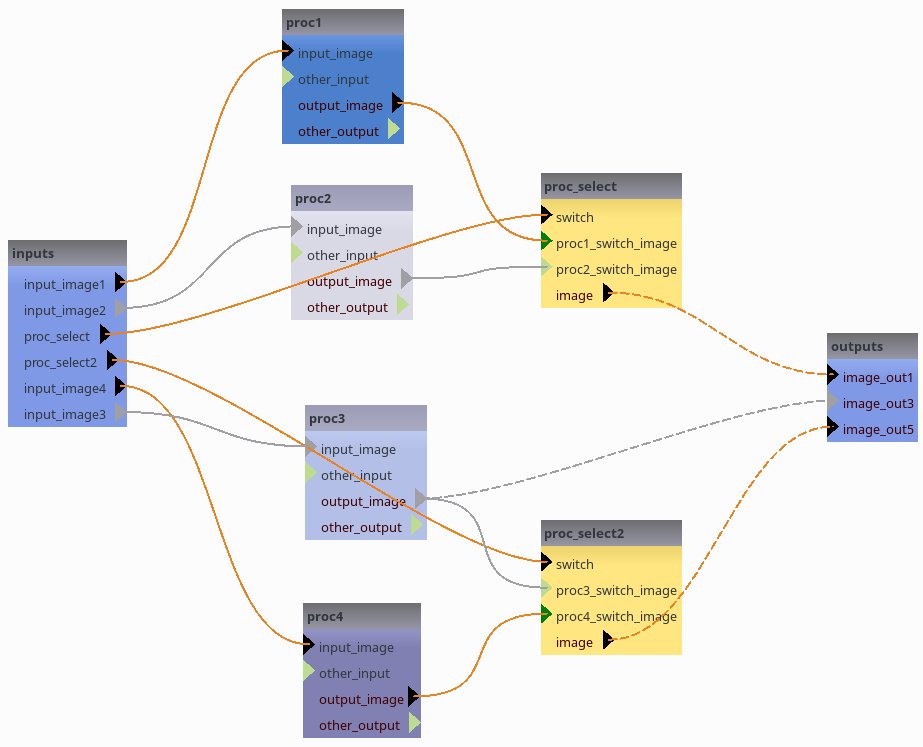
Note how the output “image_out5” depends on the proc_select2 switch value:
While “image_out1” is fixed via the FOM completion, its value “back-propagates” to both “proc1.output_image” and “proc2.output_image”. For “image_out5” the FOM does not impose its value, it is deduced from either “proc3.output_image” (in turn set via the global “image_out3”) or “proc4.output_image”, depending on the proc_select2 swtch value.
[58]:
mp.proc_select2 = "proc3"
print("switch proc_select2 value:", mp.proc_select2)
print("output image_out5:", mp.image_out5)
mp.proc_select2 = "proc4"
print("switch proc_select2 value:", mp.proc_select2)
print("output image_out5:", mp.image_out5)
switch proc_select2 value: proc3
output image_out5: /data/capsul_demo/subjects_irm2/out_image_irm2_3.nii.gz
switch proc_select2 value: proc4
output image_out5: /data/capsul_demo/subjects_irm2/out_image_irm2_4.nii.gz
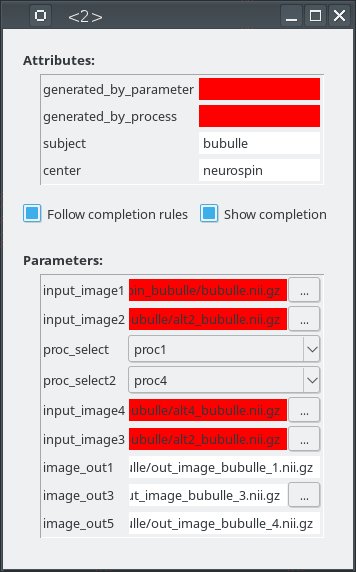
Now Cleanup the files we have created…¶
[59]:
import shutil
shutil.rmtree('/tmp/capsul_demo')